Introduction
全文字数:290
阅读时间:1 minute
本书使用mdbook构建,托管于github.io,以WSL环境为例,记录一下构建过程。
安装
安装WSL
略
打开WSL
安装Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
验证安装是否成功:
rustc --version
安装mdbook
cargo install mdbook
构建并运行
创建mdbook项目
mdbook init paper
- 是否需要
.gitignore文件:y - 输入项目名称:
paper_reading(后续可在book.toml中更改)
构建mdbook
在/paper目录下执行:
- 构建项目:
mdbook build
- 或是在浏览器中实时预览:
mdbook serve
部署
- 新建Github仓库,将项目上传至仓库。
- 在顶栏目录中找到
Actions,搜索mdbook,点击Configure,自动生成.yml文件。点击Commit Changes提交。 - 在顶栏目录中找到
Settings,在侧边栏中找到Pages,在Build and deployment下找到Source,选择Github Actions。 - 第二步会在
/paper下创建./.github/workflows/mdbook.yml文件,在本地pull更改。 - 之后本地修改内容后push到仓库,Github Actions会自动构建并部署。访问
https://<username>.github.io/<reponame>/即可查看。
参考
vector db
全文字数: 1022
阅读时间: 6 minutes
Index
| 索引算法 | 介质 | 优点 | 缺点 |
|---|---|---|---|
| Flat | 内存 | 精确 | 速度慢 |
Brute-force
Flat
暴力搜索
- 保证精确度
- 效率低
适合在小型、百万级数据集上寻求完全精确的搜索结果。
IVF
IVF_FLAT
使用倒排索引方法,结合聚类算法(如k-means),将高维空间中的向量划分为多个簇。每个簇包含相似向量,并且选取簇的中心作为代表向量。为每个簇创建倒排索引,并将每个向量映射到所属的簇。
查询时,系统只需关注相似簇,避免了遍历整个高维空间,从而显著降低了搜索复杂度。通过参数nprobe控制搜索时考虑的簇数,平衡查询精度与速度。
- IVF_FLAT将查询向量分配到距离最近的簇中心
- 然后在该簇内执行线性搜索,查找与查询向量相似的向量。
IVF_FLAT适用于需要在精度和查询速度之间取得平衡的场景,特别是在大规模高维数据集上,能够显著降低查询时间。它非常适合那些对精度要求较高,但可以容忍一定查询延迟的应用。
IVF_SQ8
IVF_SQ8 在 IVF_FLAT 基础上增加了量化步骤。IVF_SQ8通过标量量化(Scalar Quantization)将每个维度的 4 字节浮点数表示压缩为 1 字节整数表示。量化的过程是将原始的浮点数值映射到一个较小的整数范围。
- 通过量化将存储和计算资源的消耗大大降低
- 核心思想与 IVF_FLAT 类似
IVF_PQ
IVF_PQ 在 IVF_FLAT 基础上增加了 Product Quantization 步骤。将向量空间划分为更小的子空间并进行量化。
通过将向量划分为多个子空间,并对每个子空间进行独立的量化,生成一个代码本(codebook)。这样,原始的高维向量可以由多个子空间的量化表示组合而成,从而降低存储需求并加速检索。
在IVF_PQ中,乘积量化应用于IVF的聚类过程。每个簇的中心点会被进一步量化,原始的查询向量和数据向量在计算距离时,不是直接与每个簇中心进行计算,而是与每个子空间的量化中心进行计算。这种方法不仅降低了存储开销,还减少了计算距离时的运算量。
Graph-based
HNSW
HNSW(Hierarchical Navigable Small World Graph)是一种图索引算法,基于分层结构和小世界图理论,用于高效的近似最近邻搜索。它构建一个多层图结构,逐层精细化,提高高维数据集的搜索效率。
HNSW结合了跳表(Skip List)和小世界图(NSW)的技术:
- 跳表:底层为有序链表,逐层稀疏化,查询从最上层开始,逐层向下查找。
- NSW图:每个节点连接若干相似节点,使用邻接列表,从入口节点开始通过边查找最接近查询向量的节点。
HNSW工作分为两个主要阶段:索引构建和查询过程:
- 索引构建:HNSW构建多层图,每层提供不同精度和速度的搜索。最上层图提供粗粒度搜索,底层则提供更精细搜索。每个新节点连接若干近邻,形成局部小世界结构,保证图的稀疏性和高效性。
- 查询过程:查询从最上层开始,逐层向下,通过图的边接近目标。到达底层后,HNSW使用局部搜索找到最接近查询向量的结果。
DiskANN
Cluster-based
SPANN
Strategy
Graph
Graph Structure
Delaunay Graphs
Relative Neighborhood Graphs (RNG)
Navigable Small-World Networks (NSW)
Randomized Neighborhood Graphs
Dataset
Product Quantization for Nearest Neighbor Search
全文字数: 5527
阅读时间: 34 minutes
Notations
Vector quantization
量化是一种破坏性(destructive)过程,其目的是减少表示空间的基数。形式上,一个量化器(quantizer) 是一个函数 ,它将一个 维向量 映射到一个向量 ,其中索引集合 现在假设是有限的,即 。再现值(reproduction values) 被称为质心(centroids) 。再现值的集合 被称为码本(codebook) ,其大小为 。
映射到给定索引 的向量集合 被称为 (Voronoi)单元(cell),定义如下: 量化器的 个单元构成了 的一个划分。根据定义,所有位于同一单元 内的向量都由同一个质心 重构。量化器的质量通常通过输入向量 与其重构值 之间的均方误差(MSE, Mean Squared Error) 来衡量:
- 表示 和 之间的欧几里得距离
- 是对应于随机变量 的概率分布函数。
对于任意概率分布函数,通常使用蒙特卡洛采样(Monte-Carlo sampling) 进行数值计算,即在大量样本上计算 的平均值。
为了使量化器达到最优,它必须满足Lloyd 最优条件(Lloyd optimality conditions) 中的两个性质。
- 向量 必须被量化为最近的码本质心,即在欧几里得距离意义下: 因此,单元(cells)由超平面(hyperplanes) 划定。
- 重构值必须是 Voronoi 单元内向量的期望值,即:
Lloyd 量化器(Lloyd quantizer) 对应于 k-means 聚类算法,它通过迭代的方式寻找近似最优的码本,不断地将训练集中向量分配给质心,并从这些分配的向量中重新估计质心。需要注意的是,k-means 只能找到局部最优解,而非全局最优解(就量化误差而言)。
均方畸变(mean squared distortion) ,描述了当一个向量被重构到所属单元 的质心 时的误差。令: 表示一个向量被分配到质心 的概率,则该误差的计算公式如下: 均方误差(MSE)可以由这些量计算得到:
Product quantizers
乘积量化(Product quantization) 输入向量 被划分为 个不同的子向量 ,其中 ,每个子向量的维度为:
其中 是 的整数倍。这些子向量分别使用 个不同的量化器进行量化。因此,给定的向量 被映射如下:
其中 是与第 个子向量相关的低复杂度量化器。对于子量化器 ,关联索引集合 、码本 以及对应的重构值 。
乘积量化器的重构值由 乘积索引集合 的一个元素唯一标识:
因此,码本定义为笛卡尔积:
该集合的质心是 个子量化器的质心的串联。假设所有的子量化器都有相同的有限重构值数量 ,因此,总质心数为:
在极端情况下(当 ),向量 的每个分量都会被单独量化,此时 乘积量化器退化为标量量化器,其中每个分量的量化函数可能不同。
乘积量化器的优势在于可以通过多个小型质心集(子量化器的质心集合)来生成大规模质心集合。当使用 Lloyd 算法学习子量化器时,使用的样本数量有限,但码本仍然可以适应数据分布。
乘积量化器的学习复杂度是 倍于在 维度上进行 质心的 k-means 聚类的复杂度。
显式存储码本 并不高效,因此只存储所有子量化器的 个质心,即:
个浮点值。量化一个元素需要 次浮点运算。下表总结了 k-means、HKM 和乘积 k-means 的计算资源需求。乘积量化器 是唯一能在大 值时被索引存储于内存的方法。
| Method | Memory Usage | Assignment Complexity |
|---|---|---|
| k-means | ||
| HKM | ||
| Product k-means |
为了保证良好的量化性能,在 取常数时,每个子向量应具有相近的能量。一种方法是在量化前用随机正交矩阵变换向量,但对于大多数向量类型来说,这并不需要,也不推荐,因为相邻分量通常由于构造上的相关性而更适合使用相同的子量化器量化。
由于子空间正交,乘积量化器的平方畸变(Squared Distortion) 可计算为:
其中 是与子量化器 相关的畸变。
下图 显示了 MSE 随代码长度变化的曲线,其中代码长度为: ,是2的幂

可以观察到,在给定比特数的情况下,使用少量子量化器,但每个子量化器有更多质心,比使用多个子量化器但每个子量化器比特数较少要更好。
在极端情况下(当 ),乘积量化器退化为标准 k-means 码本。
高 值 会增加量化器的计算成本(如表 I 所示),同时也增加了存储质心的内存开销(即 个浮点数)。如果质心查找表无法适应缓存,则效率会降低。
在 的情况下,为了保证计算开销可控,无法使用超过 16 位的编码。通常,选择 且 是一个合理的选择。
Search
Computing distances using quantized codes
假设有一个查询向量 和一个数据库向量 。有两种方法来计算这些向量之间的近似欧几里得距离:对称距离计算(SDC) 和 非对称距离计算(ADC)。

对称距离计算(Symmetric Distance Computation, SDC):
在 SDC 方法中,查询向量 和数据库向量 均由其对应的质心 和 表示。因此,距离 近似为:
利用 乘积量化器,这个距离可以高效地计算为:
其中,距离项 从查找表中读取,该查找表与第 个子量化器相关。每个查找表包含所有质心对 之间的平方距离,即存储了 个平方距离。
非对称距离计算(Asymmetric Distance Computation, ADC):
在 ADC 方法中,数据库向量 仍由其质心 表示,但查询向量 不经过编码。因此,距离 近似为:
其计算方式如下:
其中,平方距离 在搜索之前已经计算,其中 ,。
在最近邻搜索中,实际上不会计算平方根,直接使用平方距离进行排序。
下表 总结了在数据集中搜索最近邻所涉及的不同步骤的复杂度。假设数据集 的大小为 ,可以看到 SDC 和 ADC 的查询准备成本是相同的,并且不依赖于数据集大小 。
| SDC | ADC | |
|---|---|---|
| Encoding | ||
| Compute | ||
| Compute or | ||
| Find |
当 很大()时,计算量主要由求和运算决定。而搜索 个最小元素的复杂度 是对 的元素进行无序比较的平均复杂度。
SDC 与 ADC 的对比
| Pros | Cons | |
|---|---|---|
| SDC | 减少查询向量的内存开销 | 更高的距离畸变 |
| ADC | 更低的距离畸变 | 相对较高的查询向量内存开销 |
在本文的剩余部分,将重点讨论 ADC 方法。
Analysis of the distance error
分析使用 代替 所带来的距离误差。这一分析不依赖于乘积量化器,对满足 Lloyd 最优条件的任何量化器都适用。
在重构的均方误差(MSE)准则的基础上,距离畸变(distance distortion) 通过均方距离误差(MSDE) 来衡量:
根据三角不等式有:
同样地,可以写成:
可得:
最终得到:
其中, 是与量化器 相关的均方误差。
该不等式适用于任何量化器,表明本方法的距离误差在统计意义上受量化器的 MSE 约束。
对于 对称版本(SDC),类似的推导表明其误差在统计上受 约束。因此,最小化量化误差(MSE)是重要的,因为它可以作为距离误差的统计上界。
如果在最高排名的向量上执行精确距离计算(如 局部敏感哈希(LSH)),那么量化误差可以用作动态选择需要后处理的向量集合的标准,而不是随意选择某一部分向量。
Estimator of the squared distance
分析使用 或 进行估算时,如何在平均意义上低估描述符之间的距离。
该图显示了在 1000 个 SIFT 向量数据集中查询一个 SIFT 描述符所得的距离估计。该图比较了真实距离与SDC与ADC计算出的估计值。可以清楚地看到,这些距离估计方法存在偏差(bias),且对称版本(SDC)更容易受到偏差的影响。
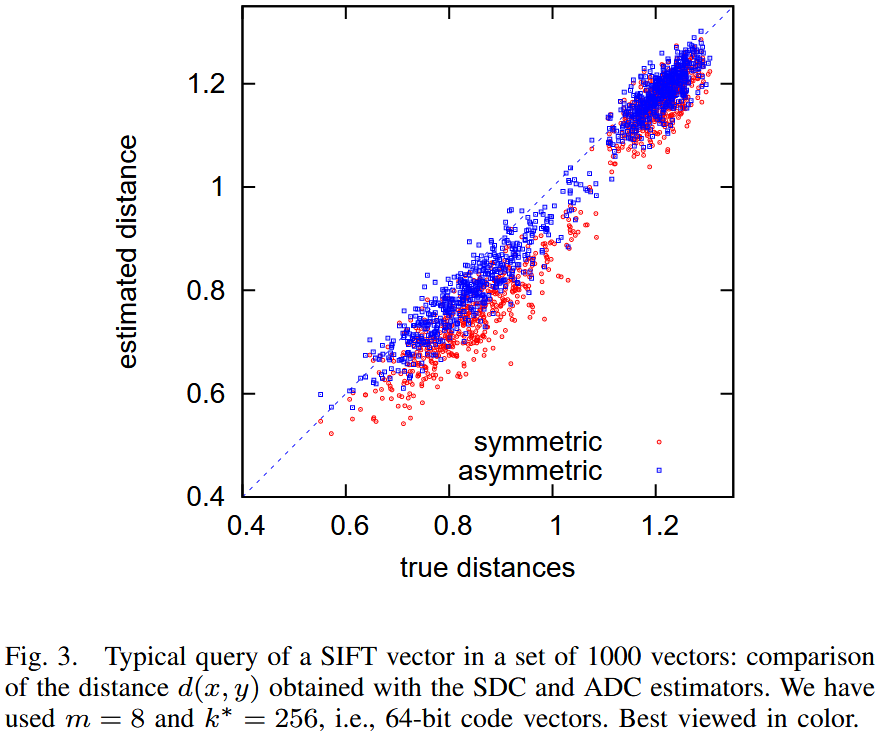
为了消除偏差,计算平方距离的期望值。在乘积量化方法中,一个给定向量 的近似值 由其子量化索引 (其中 )获得。
量化索引标识了向量 所处的单元 。因此,可以计算期望平方距离 作为修正项:
根据Lloyd 最优条件有:
因此可简化为:
其中, 代表了重构误差(distortion),即 由其重构值 近似时的误差。
在乘积量化框架下,向量 与 之间的期望平方距离可以通过修正方程 (13) 计算:
其中,修正项 为第 个子量化器的平均畸变(distortion):
这些畸变值可以预先学习,并存储在查找表中,供量化索引 使用。
对于 对称版本(SDC),即 和 均经过量化,类似的推导可以得到修正后的平方距离估计公式:
Discussion 该图显示了真实距离与估计距离之间的概率分布。该实验基于大规模 SIFT 描述符数据集。
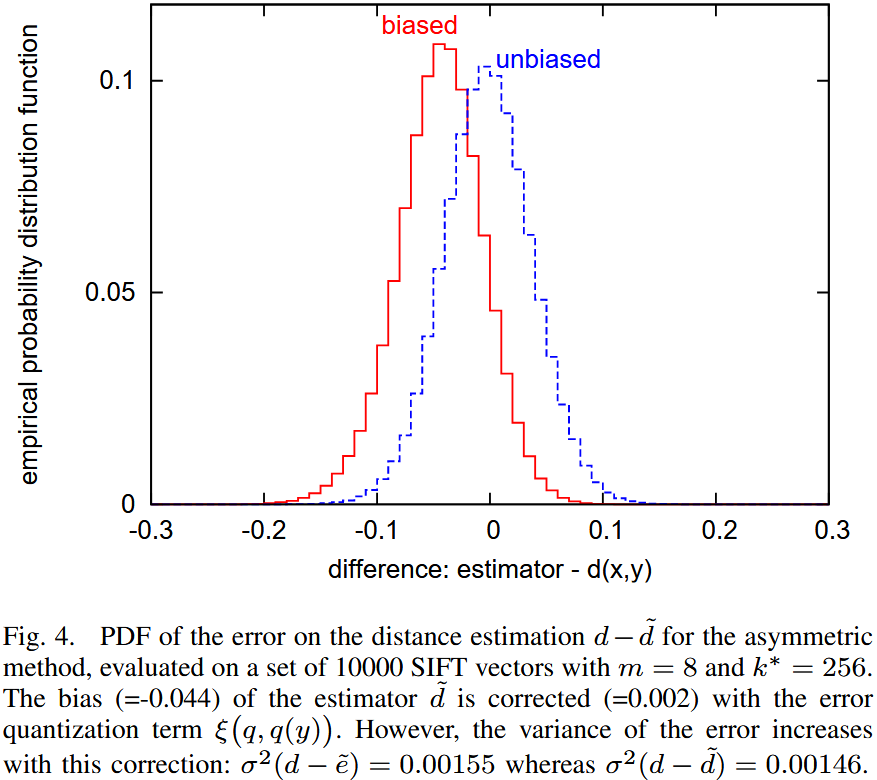
- 进行距离估计时,存在明显偏差。
- 采用 修正版本(,距离估计的偏差显著减少。
然而,修正偏差 会导致估计方差增大,这在统计学上是一个常见现象。此外,对于最近邻搜索而言:
- 修正项往往估计值更大,这可能会惩罚具有罕见索引的向量。
- 在 非对称版本(ADC) 中,修正项与查询 无关,只依赖于数据库向量 。
在实验中,修正方法在整体上效果较差,因此建议在最近邻搜索任务中使用原始版本,而修正版本仅在需要精准距离估计的任务中适用。
Avoid exhaustive search
使用乘积量化器进行近似最近邻搜索非常高效(每次距离计算仅需 次加法运算),并且大大减少了存储描述符所需的内存。然而,标准搜索方法是穷举式(Exhaustive)的。
为了避免穷举搜索:
- 倒排文件系统(Inverted File System, IVF)
- 非对称距离计算(ADC)
该方法称为 IVFADC。
传统倒排文件仅存储图像索引,而本文在此基础上增加了额外的编码,以便对每个描述符进行更精细的存储。使用乘积量化器对向量与其对应的粗质心之间的残差进行编码。
- 显著加速搜索过程,代价仅是每个描述符存储额外的少量比特/字节。
- 提高搜索精度,因为对残差进行编码比直接编码向量本身更加精确。
Coarse quantizer, locally defined product quantizer
码本(codebook)是通过 k-means 学习得到的,并生成了一个量化器 ,在后续内容中称为 粗量化器(coarse quantizer)。对于 SIFT 描述符,与 相关的质心(centroid)数量 通常在 1000 到 1000000 之间。因此,与 乘积量化器相比,粗量化器的规模较小。
除了粗量化器,还使用乘积量化器对向量的描述进行细化。具体来说,粗量化器 生成的质心可以提供全局信息,但仍需进一步编码残差信息,因此使用 乘积量化器 对残差向量进行编码:
其中,残差向量 表示 Voronoi 单元中的偏移量。由于残差向量的能量相比原始向量要小,因此存储其量化信息的代价也较低。
向量 可被近似表示为:
它可以用元组 来表示。
类比于二进制表示的概念:
- 粗量化器() 提供的是最高有效位(MSB),用于大致定位向量。
- 乘积量化器() 提供的是最低有效位(LSB),用于精细校正残差信息。
查询向量 和数据库向量 之间的距离可以近似计算为 :
令 表示第 个子量化器(Subquantizer),则可分解计算该距离:
类似于 ADC(Asymmetric Distance Computation) 策略,对于每个子量化器 ,预计算部分残差向量 与所有质心 之间的距离,并存储这些值。
乘积量化器是在一个学习集合中通过残差向量训练得到的。虽然向量最初由粗量化器映射到不同的索引,但最终的残差向量被用于训练一个统一的乘积量化器。
假设当残差在所有 Voronoi 单元上进行边际化(Marginalization)时,相同的乘积量化器仍然有效。然而,这种方法的效果可能不如为每个 Voronoi 单元单独训练一个独立的乘积量化器,但后者的计算成本极高。如果要为每个 Voronoi 单元分别训练乘积量化器,则需要存储 个乘积量化码本,即:
个浮点值。这对于典型的 值来说,将会导致极高的存储需求,在实际应用中难以承受。
Indexing structure
使用粗量化器(coarse quantizer)来实现一种倒排文件结构(inverted file structure),它被组织成一个包含列表的数组 。如果 是要索引的向量数据集,那么与质心 相关联的列表 将存储集合 。
在倒排列表 中,与 相关的条目包含一个向量标识符(vector identifier)和编码后的残差 :
| field | length(bits) |
|---|---|
| identifier | 8–32 |
| code |
标识符字段是倒排文件结构带来的开销。根据存储向量的不同特性,标识符不一定是唯一的。例如,在使用局部描述符(local descriptors)表示图像时,图像标识符可以替代向量标识符,即同一张图像的所有向量都可以使用相同的标识符。因此,20 位的标识符字段足以在一个包含一百万张图像的数据集中唯一标识一张图像。
通过索引压缩(index compression)可以进一步降低存储开销,使存储标识符的平均成本降低到约 8 比特,具体取决于参数。
Search algorithm
倒排文件(inverted file)是非穷尽(non-exhaustive)的关键。当搜索向量 的最近邻时,倒排文件提供了一个 的子集,用于计算距离:仅扫描与 对应的倒排列表 。
然而, 及其最近邻通常不会被量化到同一个质心,而是被量化到相邻的质心。为了解决这个问题,采用 多重分配(multiple assignment) 策略 。查询向量 被分配到 个索引,而不是仅仅一个索引,这些索引对应于 代码本 中 的 个最近邻。然后,扫描所有相应的倒排列表。多重分配不会用于数据库向量,因为这会增加内存占用。
下图概述了数据库的索引和搜索过程。
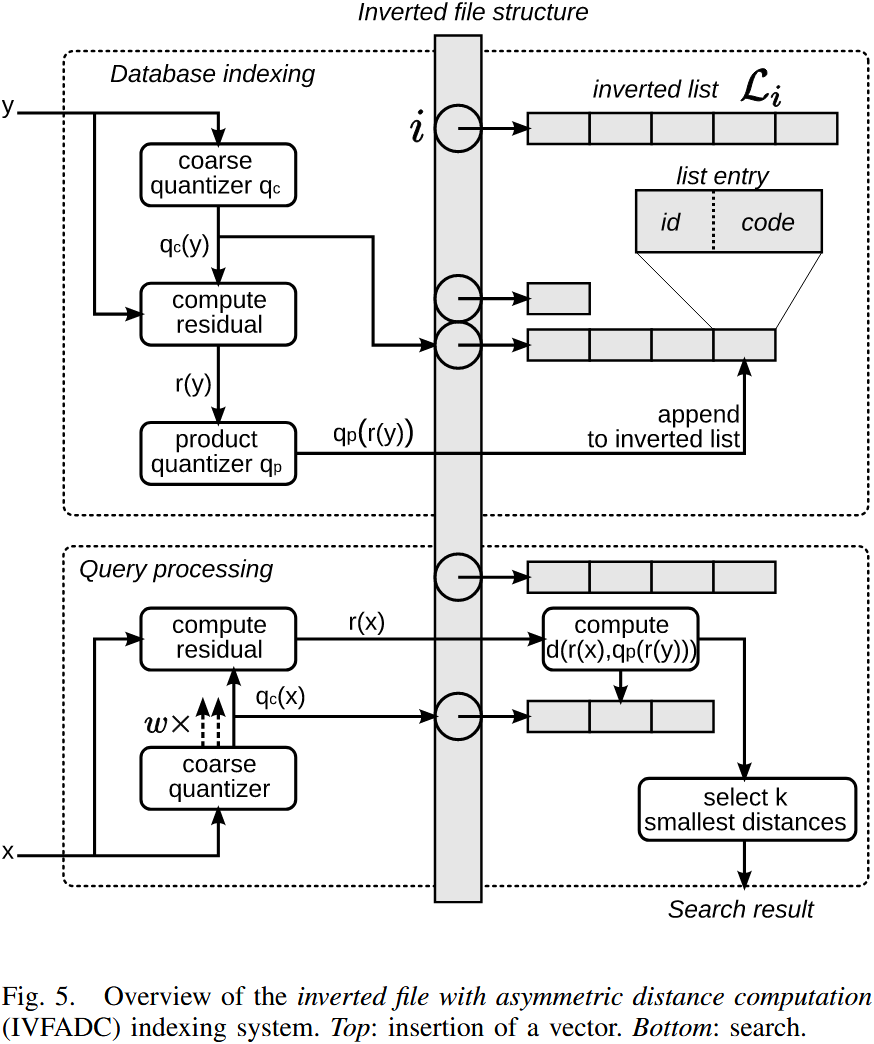
索引(Indexing)向量 的过程如下:
- 对 进行量化,得到 ;
- 计算残差(residual):;
- 对残差 进行量化,得到 ,对于乘积量化器(product quantizer),这意味着将 映射到 ,其中 ;
- 向倒排列表 添加新条目,该条目包含 向量(或图像)标识符 和 二进制编码(即乘积量化器的索引)。
查询(Searching)最近邻 的过程如下:
-
将 量化到代码本 中最近的 个质心;
为了便于表述,接下来的两步中简单地用 来表示与这些 个分配相关的残差。这两个步骤适用于所有 个分配。
-
计算平方距离 ,对于每个子量化器 以及其所有质心 ;
-
计算 与倒排列表中所有索引向量的平方距离;
使用上一步计算的子向量到质心距离,最终得到总距离。这一过程涉及查找 个预计算值(见公式 31)。
-
根据估计距离选择 个最近邻:
- 这一过程使用 最大堆(Maxheap) 结构(固定容量)来存储 当前已找到的 个最小距离;
- 每次计算距离后,仅当该点的距离小于最大堆中当前的最大距离时,才将其插入数据结构。
只有第 3 步 依赖于数据库的大小。与 ADC(Asymmetric Distance Computation,非对称距离计算) 相比,额外的 量化 到 仅涉及计算 个 D 维向量的距离。假设倒排列表是均衡的,则需要解析 个条目。因此,该搜索方法比 ADC 显著更快。
Characterizing the Dilemma of Performance and Index Size in Billion-Scale Vector Search and Breaking It with Second-Tier Memory
全文字数: 2671
阅读时间: 16 minutes
Background
Second-tier memory(如通过 RDMA 或 CXL 连接的远程 DRAM/NVM)具有 细粒度的访问能力,能够有效解决 搜索粒度与访问粒度不匹配 的问题。
然而:
- 现有索引主要针对 SSD 设计,在 second-tier memory 上表现不佳。
- Second-tier memory 的行为更类似于存储,使其像 DRAM 那样使用时效率较低。
为此,本文提出了一种专为 second-tier memory 性能特性优化的 图索引与簇索引 方案,具有以下优势:
- 最优性能
- 数量级更小的索引放大
High Performance and Low Index Size Dilemma
增大索引大小可以提升性能:
- 对于 图索引(graph indexes),增加更多的边可以减少跳数(I/O 操作)。
- 对于 簇索引(cluster indexes),在簇之间复制相邻向量可以减少搜索的簇数量。
相反,缩小索引大小会导致性能下降。一种在不改变算法的情况下减少索引大小的替代方案是 复制地址而不是重复存储向量。然而,这种方法会引入额外的小随机读操作,在 SSD 上会显著降低性能。
根本原因:工作负载模式与 SSD 要求不匹配
- SSD 的页面通常为 4KB,而 second-tier memory 支持 更细粒度的 256B 访问。
- 图索引和簇索引 的读取操作通常仅涉及 几百字节的数据。
Graph Index
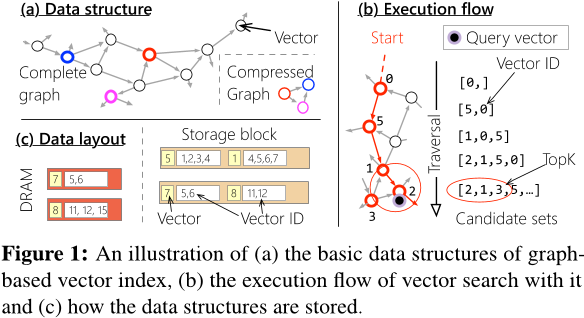
- 图索引(Graph indexes) 能够捕捉向量之间的细粒度关系,使得在访问 top-k 以外的少量额外向量时,保持较低的读取放大(read amplification)。
- 然而,其 指针跳转(pointer-chasing) 访问模式导致 高延迟,并且 带宽利用率较低。
在 DiskANN 中,每个向量默认分配 32 条边,每条边由 4B 向量 ID 表示。这意味着边列表的大小可能会超过原始数据的大小。例如,在 SPACEV 中,一个大小为 100B 的顶点需要 128B 来存储其边信息。
理想情况下,边所引起的空间放大应尽可能减少。然而,减少边的数量会增加查询向量的 遍历距离(traversal distance)。
即使增加边的数量,每次图遍历的加载量仍然受限于 SSD 的访问粒度(4KB)。如果超出此限制,索引大小将急剧膨胀,甚至可能达到原始数据集大小的 39 倍。例如,一个 100B 的节点若使用 3,996B 存储边信息,将导致 极高的空间占用。
Cluster Index
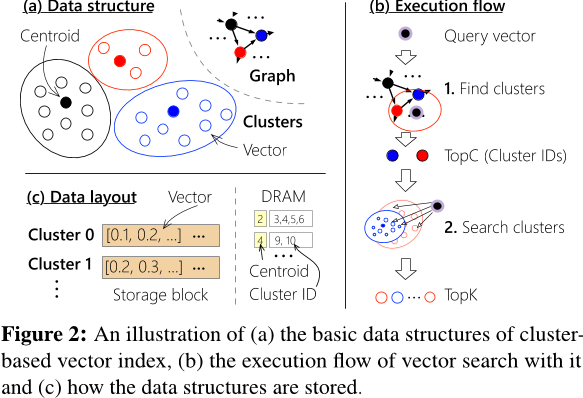
- 存储效率高,支持 大批量读取(large bulk reads) 簇数据。
- 由于簇内存在冗余向量读取,导致 高读取放大(read amplification)。
- 向量复制 造成 高空间放大(space amplification)。
理想情况下,簇索引的大小应尽可能小:
- 簇的索引数据 远小于整个数据集的规模,通常相差数个数量级。
- 每个簇可能跨越多个块,因此不需要填充(padding)。
为了 解决边界问题导致的准确率下降,相邻簇之间会复制 边界向量(boundary vectors),这需要 额外的索引存储空间。
为 减少过多的向量复制,一种替代方案是 增加每次查询搜索的簇数量。但 额外的簇搜索 会导致 额外的向量读取,从而 降低性能。
经验上来看,增加索引大小仍然可以提升吞吐量(throughput)。
Workloads Mismatch SSD Requirements
-
图索引(Graph index) 需要 细粒度的存储读取 以保持可接受的索引大小。然而,这与 使用足够大的 I/O 负载(4 KB) 来高效利用 SSD 等传统存储设备 的需求相冲突。
-
簇索引(Cluster index) 需要 不规则 I/O 来进行 去重(deduplication)。与其在其他簇中存储重复的向量数据,不如 存储一个指向原始簇的地址。向量地址(8B) 远小于实际数据(128–384B)。然而,这意味着每个被复制的向量都需要 单独的小随机读(100–384B) 来获取原始向量,进而影响读取性能。
Power of Second-tier Memory
-
细粒度块大小(Fine-grained block sizes)
- 更高效地利用设备带宽
-
对不规则 I/O 具有更强的适应性(Robust to irregular I/O)
- 将(部分)顺序访问 替换为 随机访问
Improvement
Graph Index
Software Pipeline
在发出second-tier memory请求后,立即调度下一个未完成的查询执行,从而在软件层面以流水线方式高效处理不同的查询。
Compressed Layout
DiskANN 采用填充方式进行存储,这种填充设计会浪费索引空间。在 second-tier memory 上,由于其能够有效适应 跨块大小的不规则 I/O,填充设计已无必要。因此直接选择 压缩稀疏行(Compressed Sparse Row,CSR) ,以减少存储空间占用,同时保持性能稳定。
Cluster Index
Decoupled Layout
向量数据采用独立存储,而每个簇仅存储对应向量的地址(b)。这样,对于需要复制的向量,仅复制地址,而无需复制向量本身,从而有效减少存储开销。
尽管decoupled Layout有助于缩小索引大小,但它将原本0.1–2.2 MB 的顺序 I/O 拆分为 60–68 次小随机 I/O(每次读取 100–384B)。更具体而言,工作负载中的 98% I/O 变成了小随机读取,而在 second-tier memory 上,这些 I/O 操作的效率同样不高。
Vector Grouping
为减少工作负载中的 小 I/O 操作,在 decoupled design 之上提出了 向量分组(vector grouping) 方法,以尽量减少 小随机 I/O。通过 将同一簇的向量分组存储在相邻的存储位置,可以使用 一次大 I/O 操作 读取整个分组的向量数据(见 图 11(c))。分组操作 在 索引构建后(post index build) 进行。
由于 不复制向量,必然会存在某些簇无法通过一次 I/O 读取其所有向量。因此,分组的性能 主要取决于 向量如何被分组。
向量分组的目标是 确定哪些向量应该被分组,以减少给定工作负载中的小 I/O。这等价于 向特定簇分配向量 的问题。假设在一个向量数据库中,向量集合为 V,簇集合为 C,使用 $P_{i,j}$ 表示 第 i 个向量是否被分配到某个分组。
采用 整数线性规划(Integer Linear Programming, ILP) 来找到 $P_{i,j}$ 的最优分组,目标是 最小化发往存储管理节点(MN)的 I/O 请求。由于 I/O 数量取决于 每个簇的访问频率,我们使用 $h_{j}$ 来表示 簇 j 的访问频率。
这些频率可以通过 后台监控工作负载 获得,并可以根据 访问频率的变化 动态调整布局。
综合以上内容,问题可被公式化如下:
$$ \text{min} \sum_{j}^{|C|} h_j \cdot \left(1 + \sum_{i}^{|V|} P_{i,j}\right) $$
约束条件:
-
簇约束(Cluster constraints)
根据簇索引设计,每个向量必须 分配到一个簇,但可以 复制到多个相邻簇。约束条件如下:$$ \begin{cases} 0 \leq A_{i,j} \leq 1, \quad i \in [0, |V|], j \in [0, |C|] \ \sum_{j}^{|C|} A_{i,j} \geq 1, \quad i \in [0, |V|] \end{cases} $$
-
分组约束(Group constraints)
分组算法必须将 一个向量分配给唯一的簇组,约束如下:$$ \begin{cases} 0 \leq P_{i,j} \leq 1, \quad i \in [0, |V|], j \in [0, |C|] \ \sum_{j}^{|C|} P_{i,j} = 1, \quad i \in [0, |V|] \end{cases} $$
Conclusion
Second-tier memory is a promising storage medium for vector indexes.
NSG
Introduction
单调相对邻近图(MRNG,Monotonic Relative Neighborhood Graph)
- 保证连通性
- 降低平均出度
- 缩短搜索路径
- 减少索引大小
设计了 MRNG 的近似结构,称为 导航扩展图(NSG)
DiskANN
全文字数: 12808
阅读时间: 80 minutes
Background
DiskANN系列主要包含三篇论文:
- DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node
- FreshDiskANN: A Fast and Accurate Graph-Based ANN Index for Streaming Similarity Search
- Filtered − DiskANN: Graph Algorithms for Approximate Nearest Neighbor Search with Filters
SNG
DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node
Algorithm
GreedySearch
大多数基于图的近似最近邻搜索(ANN)算法的工作方式如下:在索引构建过程中,它们根据数据集 的几何属性构建图 。在搜索时,对于查询向量 ,搜索采用自然的贪心或最优优先遍历,如算法1中的方式,在图 上进行。从某个指定的点 开始,它们遍历图以逐步接近 。
在SNG中,每个点 的外部邻居通过以下方式确定:初始化一个集合 。只要 ,从 到 添加一条有向边,其中 是离 最近的点,从集合 中移除所有使得 的点 。因此,贪心搜索(GreedySearch(s, , 1))从任何 开始都将收敛到 ,对于所有基点 都成立。

RobustPrune
满足SNG性质的图都是适合贪心搜索搜索过程的良好候选图。然而,图的直径可能会相当大。例如,如果点在实数线的一维空间上线性排列,图的直径是 ,其中每个点连接到两个邻居(一个在两端),这样的图满足SNG性质。搜索此类存储在磁盘上的图将导致在搜索路径中访问的顶点的邻居需要大量的顺序读取。
为了解决这个问题,希望确保查询距离在搜索路径的每个节点上按乘法因子 递减,而不仅仅是像SNG性质那样递减。

Vamana Indexing
Vamana 以迭代的方式构建有向图 。
- 图 被初始化,使得每个顶点都有 个随机选择的外部邻居(在 时连接良好)。
- 让 表示数据集 的中心点,它将作为搜索算法的起始节点。
- 算法按随机顺序遍历 的所有点,并在每一步更新图,使其更加适合贪心搜索(GreedySearch(s, , 1, L))收敛到 。
实际上,在对应点 的迭代中,
- Vamana 在当前图 上运行 GreedySearch(s, , 1, L),并将 设置为贪心搜索路径中所有访问过的点的集合。
- 算法通过运行 RobustPrune(p, , , ) 来更新图 ,以确定 的新外部邻居。
- Vamana 更新图 ,通过为所有 添加反向边()。这确保了在搜索路径和 之间的顶点连接,从而确保更新后的图会更适合贪心搜索(GreedySearch(s, , 1, L))收敛到 。
- 添加这种形式的反向边()可能会导致 的度数超过阈值,因此每当某个顶点 的外度超过 的度数阈值时,图通过运行 RobustPrune(, , , ) 来修改,其中 是 的现有外部邻居集合。
算法对数据集进行两次遍历,第一次遍历使用 ,第二次使用用户定义的 。


Design
Index Design
在数据集 上运行 Vamana,并将结果存储在 SSD 上。在搜索时,每当算法1需要某个点 的外部邻居时, 从 SSD 中获取该点的信息。
然而,单纯存储包含十亿个100维空间中的向量数据远超过工作站的RAM!这引出了两个问题:
- 如何构建一个包含十亿个点的图?
- 如果不能在内存中存储向量数据,如何在算法1的搜索时执行查询点与候选点之间的距离比较?
问题一
通过聚类技术(如k-means)将数据划分成多个较小的分片,为每个分片建立一个单独的索引,并仅在查询时将查询路由到几个分片。然而,这种方法会因为查询需要路由到多个分片而导致搜索延迟增加和吞吐量减少。
与其在查询时将查询路由到多个分片,不如将每个基础点发送到多个相邻的中心以获得重叠的聚类。事实上,我们将一个十亿点的数据集通过k-means划分为k个聚类(k=40,通常ℓ=2就足够),然后将每个基础点分配给ℓ个最近的中心。接着,我们为分配给每个聚类的点建立Vamana索引(这些点现在只有约Nℓ/k个点,可以在内存中建立索引),最后通过简单的边缘合并将所有不同的图合并为一个单一的图。
问题二
将每个数据库点 的压缩向量 存储在主存中,同时将图存储在SSD上。使用Product Quantization将数据和查询点编码为短代码在查询时高效地计算近似距离 。尽管在搜索时只使用压缩数据,但是Vamana在构建图索引时使用的是“全精度坐标”,因此能够高效地引导搜索到图的正确区域,
Index Layout
将所有数据点的压缩向量存储在内存中,并将图以及全精度向量存储在SSD上。在磁盘中,对于每个点 ,我们存储其全精度向量 ,并跟随其 个邻居的标识。如果一个节点的度小于 ,我们用零填充,以便计算数据在磁盘中对应点 的偏移量变得简单,并且不需要在内存中存储偏移量。
Beam Search
运行算法1,按需从SSD获取邻居信息 。这需要很多次SSD的往返(每次往返仅需几百微秒),从而导致更高的延迟。为了减少往返SSD的次数(以便顺序地获取邻居),而不过多的增加计算量,一次性获取一个较小数量 (例如4、8)最近的点的邻居,并将 更新为这一小步中的前 个最优点。从SSD获取少量随机扇区的时间几乎与获取一个扇区的时间相同。
- 如果 ,这种搜索类似于正常的贪婪搜索。
- 如果 太大,比如16或更多,则计算和SSD带宽可能会浪费。
Caching Frequently Visited Vertices
为了进一步减少每个查询的磁盘访问次数,缓存与一部分顶点相关的数据,这些顶点可以基于已知的查询分布来选择,或者通过缓存所有距离起始点 为 或 跳的顶点来选择。
由于索引图中与距离 相关的节点数量随着 增加呈指数增长,因此较大的 值会导致过大的内存占用。
Implicit Re-Ranking Using Full-Precision Vectors
由于PQ是一种有损压缩方法,因此使用基于PQ的近似距离计算出的与查询最接近的 个候选点之间存在差距。为了解决这个问题,使用存储在磁盘上与每个点相邻的全精度坐标。
事实上,在搜索过程中检索一个点的邻域时,也可以在不增加额外磁盘读取的情况下获取该点的全精度坐标。这是因为读取4KB对齐的磁盘地址到内存的成本不高于读取512B,而顶点的邻域(对于度为128的图,邻域大小为 字节)和全精度坐标可以存储在同一磁盘扇区中。
因此,随着BeamSearch加载搜索前沿的邻域,它还会缓存在搜索过程中访问的所有节点的全精度坐标,而不需要额外的SSD读取操作。这使得我们能够基于全精度向量返回前 个候选点。
Evaluation
(具体实验条件参见论文)
- 内存搜索性能比较
- NSG和Vamana在所有情况下recall@100都优于HNSW
- Vamana的索引构建时间优于HNSW和NSG
- 跳数(搜索中基于图的跳跃次数)比较
- Vamana更适合用于基于SSD的搜索,其在大型数据集上比HNSW和NSG要快2到3倍。
- 随着最大度数的增加,HNSW和NSG跳数出现了停滞趋势,而Vamana跳数有所减少,因为它能够增加更多的长距离边缘。推测Vamana在 时,比HNSW和NSG更好地利用了SSD提供的高带宽(在BeamSearch中,通过最大化𝑊来扩展搜索进行更大的磁盘读取)。
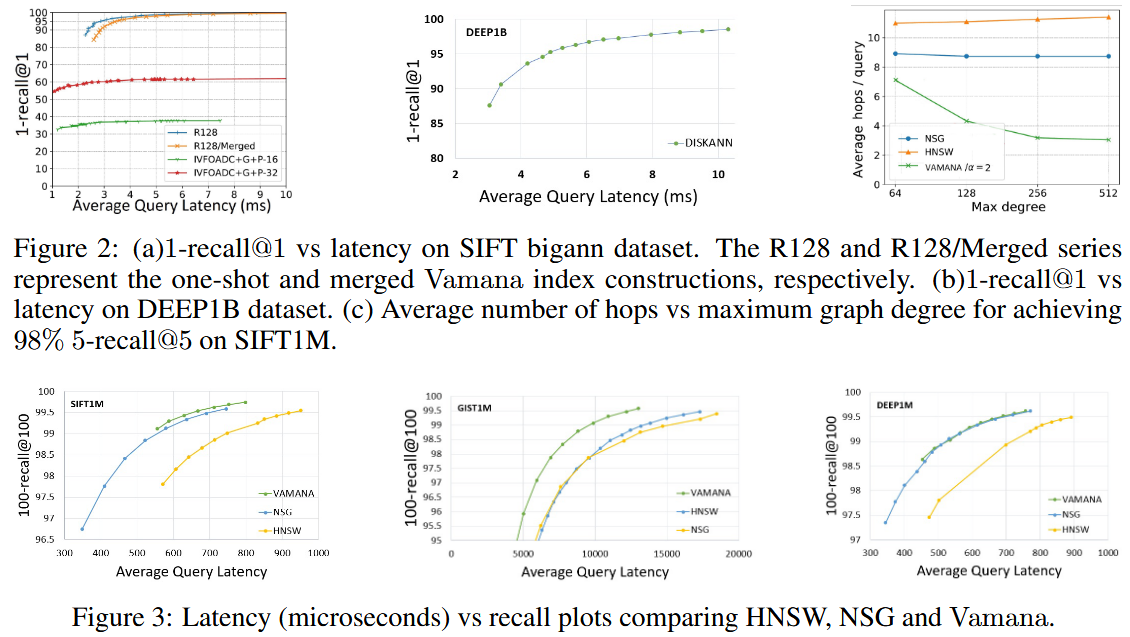
- One-Shot Vamana 和 Merged Vamana
- Single:2 days, degree=113.9, peek memory usage=1100GB
- Merged:5 days, degree=92.1, peek memory usage<64GB
- 单一索引优于合并索引,合并索引的延迟更高
- 合并索引仍是十亿规模k-ANN索引和单节点服务的一个非常好的选择:相比单一索引,目标召回时只需增加不到20%的额外延迟
FreshDiskANN: A Fast and Accurate Graph-Based ANN Index for Streaming Similarity Search
Introduction
在许多重要的现实场景中,用户与系统的交互会创建并销毁数据,并导致 的更新。针对这种应用的ANN系统需要能够托管包含数万亿个实时更新点的索引,这些更新可以反映数据集中的变化,理想情况下是实时进行的。
形式上定义 fresh-ANNs 问题如下:给定一个随时间变化的数据集 (在时间 时的状态为 ),目标是维护一个动态索引,该索引计算任何查询 在时间 时,仅在活动数据集 上的近似最近邻。这样的系统必须支持三种操作:
- (a)插入新点,
- (b)删除现有点,以及
- (c)给定查询点进行最近邻搜索。
一个 fresh-ANNs 系统的总体质量由以下几个方面来衡量:
- 搜索查询的召回率与延迟之间的权衡,以及随着数据集 演变其对时间的鲁棒性。
- 插入和删除操作的吞吐量与延迟。
- 构建和维护此类索引所需的整体硬件成本(CPU、RAM 和 SSD 占用)。
freshDiskANN 注重于 quiescent consistency 的概念
quiescent consistency: the results of search operations executed at any time t are consistent with some total ordering of all insert and delete operations completed before t.
quiescent consistency(静默一致性)是指在系统中执行的操作(如搜索、插入和删除)的结果,在某个时刻(如时间 𝑡)前的所有操作都已经完成,并且这些操作的结果与已执行的操作的顺序保持一致。如果一个查询需要依赖于之前的插入或删除操作,那么在查询时,插入和删除操作应已完成,并且查询结果应该基于这些已完成的操作。
删除操作为什么难以实现?
HNSW算法通过将删除的点添加到黑名单并将其从搜索结果中省略来处理删除请求,因为缺乏能够在保持原始搜索质量的同时修改可导航图的方法。考虑三种流行的静态ANNS算法,分别是HNSW、NSG和Vamana,并尝试了以下自然更新策略,看看在面对插入和删除操作时它们的表现。
- 插入策略。 对于插入一个新点 ,运行相应算法使用的候选生成算法,并添加选定的入边和出边;如果任何顶点的度数超过预算,则运行相应的修剪过程。
-
- 删除策略A。 当删除一个点 时,简单地删除与 相关的所有入边和出边,而不添加任何新边以弥补潜在的可导航性丧失。
- 删除策略B。 当删除一个点 时,移除所有与 相关的入边和出边,并在 的局部邻域中添加边:对于图中的每对有向边 和 ,在更新的图中添加边 。如果任何顶点的度数超过限制,则运行相应算法的修剪过程来控制度数。
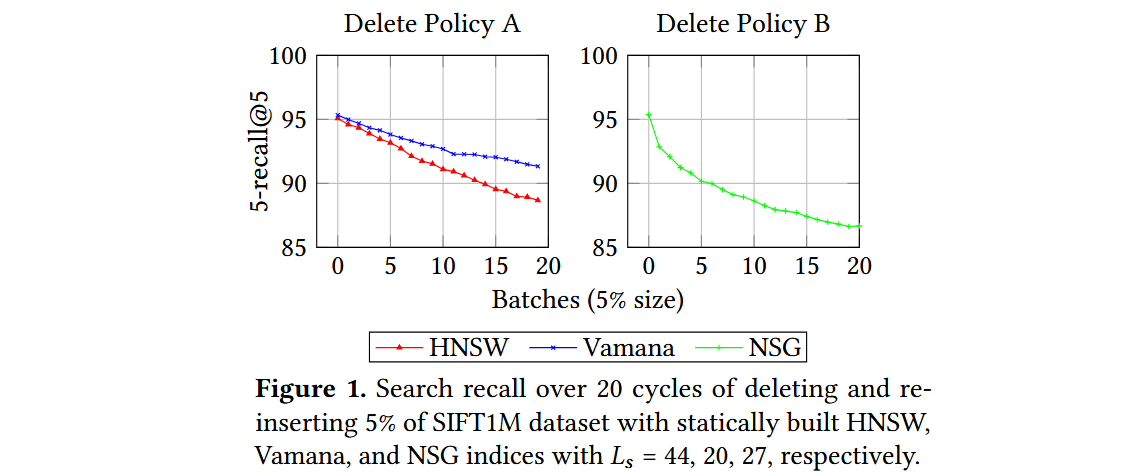
一个稳定的更新策略应该在每个周期之后产生相似的搜索性能,因为索引是建立在相同的数据集上的。然而,所有算法都表现出搜索性能持续下降的趋势。
FreshVamana
随着图的更新,图变得稀疏(平均度数较小),因此变得不那么可导航。怀疑这是由于现有算法(如HNSW和NSG)使用非常激进的修剪策略来偏向稀疏图所导致的。
α-RNG Property. DiskANN中构建的图的关键思想是采用更为宽松的剪枝过程,它仅在存在一条边 且 必须比 更接近 时才移除边 ,即 ,其中 。使用 生成这样的图直观地确保了查询向量到目标向量的距离在算法 1 中以几何方式逐步减小,因为只移除那些存在绕道边,使得s'yu显著朝目标方向推进的边。因此,随着 的增加,图变得更加密集。利用α-RNG属性,确保图的持续可导航性,并保持多个插入和删除操作过程中的稳定召回率。
Algorithms
GreedySearch 与 DiskANN中的算法1相同
Index Build
构建一个可导航图。图的构建通常有两个对立的目标,以最小化搜索复杂度:
- 使应用到每个基点 上的贪心搜索算法在最少的迭代中收敛到
- 使所有 的最大出度 不超过
从初始图开始,经过以下两步构建算法逐步精炼G,以提高可导航性。
- 生成候选 : 对于每个基点 ,在图 上运行算法1(从固定的起始点s开始)来获得 ,其中 包含最接近 的节点,将它们添加到 和 的良好候选,从而提高更新图G中对 的可导航性。
- 边修剪 : 当节点 的出度超过 时,修剪算法(如算法3,)会从邻接列表中过滤出类似的(或冗余的)边,以确保 。过程会按距离 的增大顺序对其邻居进行排序,如果算法1能够通过 从 到达 ,则可以安全地移除边 )。
Insertion
- 对于新插入的点 ,从起始点 开始运行,将访问过的点保存在中。
- 将后的结果集合作为的邻居。
- 对的每一个邻居进行剪枝,确保其加入新邻居后的度数不超过。


Deletion
- 对于删除后的图中剩余的每一个点,检查其出边是否包含已删除的点,若有则继续
- 将出边中包含的已删除点的邻居加入到集合中
- 将出边中其余的点加入到集合中
- 对于集合中的每一个点,将其邻居加入到集合中
- 在集合中排除那些已经被删除的点()
- 运行来更新其出边

算法 4 参考了上文中的 删除策略B,关键特性是使用宽松的 -剪枝算法来保持修改后图的稠密性。具体而言,如果删除点 ,则在图中添加边 ,其中 和 是有向边。在此过程中,如果 超过最大出度 ,我们使用算法 3 对其进行剪枝,以保持 -RNG 性质。
然而,由于该操作涉及编辑 的所有入邻居的邻域,代价可能很大,无法在删除到达时立即处理。FreshVamana 采用了懒删除策略 —— 当一个点 被删除时,我们将 添加到 DeleteList 中而不改变图。DeleteList 包含所有已删除但仍存在于图中的点。在搜索时,修改后的算法 1 会使用 DeleteList 中的节点进行导航,但会从结果集中筛选掉它们。
删除合并。在累积了大量删除操作(例如,索引大小的 1%-10%)后,使用算法 4 批量更新图,以更新有出边的点的邻居,从而将这些删除的节点更新到图中。

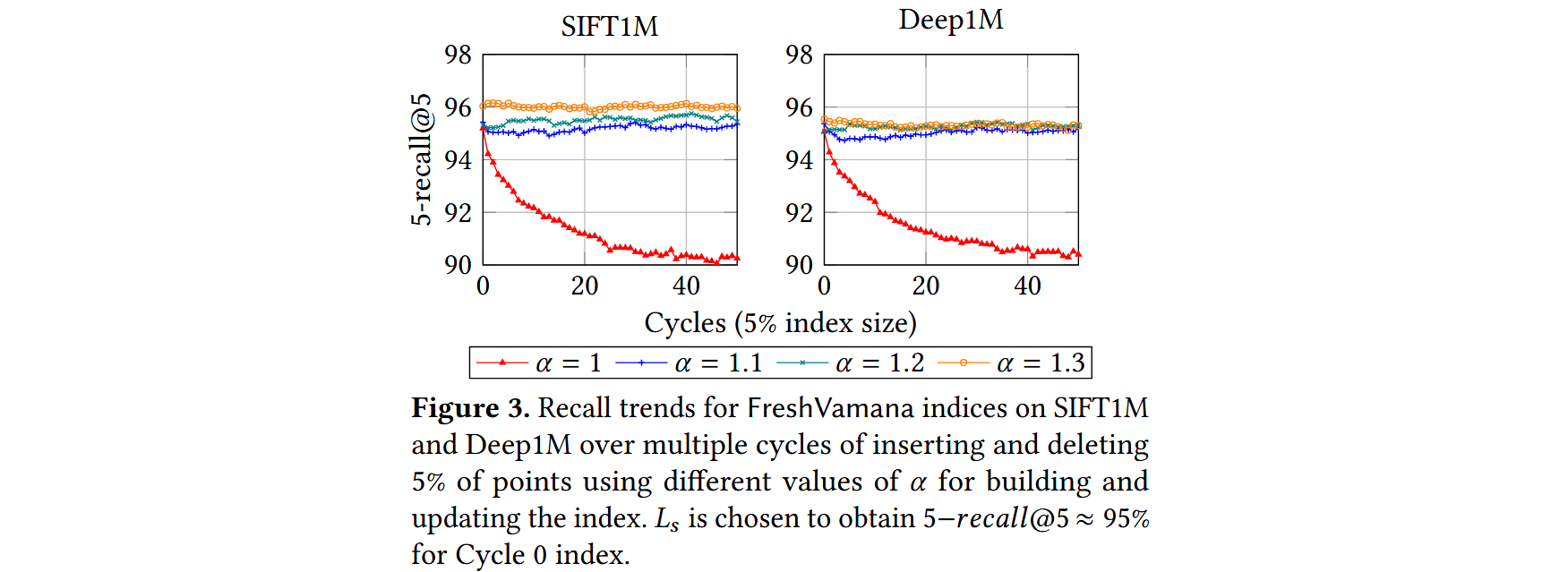
- 一组良好的更新规则应能保持召回率在这些循环中稳定。
- 除 𝛼 = 1 外,所有索引的召回率都是稳定的,这验证了使用 𝛼 > 1的重要性。
FreshDiskANN system
FreshDiskANN 系统的主要思想是将大部分图索引存储在 SSD 上,仅将最近的更改保存在 RAM 中。
为了进一步减少内存占用,可以仅存储压缩向量来表示所有数据向量。使用 -RNG 图并仅存储压缩向量的思想构成了基于 SSD 的 DiskANN 静态 ANNS 索引的核心。
由于无法直接在 SSD 驻留的 FreshVamana 索引上运行插入和删除算法。插入一个新点 需要更新至多 个邻居以向 添加边,这将触发最多 次随机写入 SSD。意味着每次插入都需要进行同等数量的随机 SSD 写入。这将严重限制插入吞吐量,并降低搜索吞吐量(SSD 上的高写入负载会影响其读取性能)。如果每次删除操作都立即执行,则会导致 次写入。
FreshDiskANN 系统规避了这些问题,并通过拆分索引为两部分,将基于 SSD 的系统的效率与基于内存系统的交互式低延迟结合起来:
- 内存中的 FreshVamana 组件:用于存储最近的更新;
- 驻留在 SSD 上的索引:用于存储长期数据。
Components
系统维护两种索引:长期索引(Long-Term Index,LTI)和一个或多个临时索引(Temporary Index,TempIndex),以及删除列表(DeleteList)。
- LTI 是驻留在 SSD 上的索引,用于支持搜索请求。它的内存占用很小,每个点的存储仅包含约 25-32 字节的压缩表示。其关联的图索引和完整精度数据存储在 SSD 上。插入和删除操作不会实时影响 LTI。
- 、TempIndex,完全存储在DRAM 中的 FreshVamana 索引实例(包括数据和相关图结构)。TempIndex 存储了最近插入的点 。内存占用仅占整个索引的一小部分。
- DeleteList 其中的点存在于 LTI 或 TempIndex 中,但已被用户请求删除。此列表用于过滤搜索结果中已删除的点。
- RO- 和 RW-TempIndex 为了支持崩溃恢复,FreshDiskANN 使用两种类型的 TempIndex。在任何时候,FreshDiskANN 都会维护一个可变的可读写 TempIndex(称为 RW-TempIndex),它可以接受插入请求。定期将 RW-TempIndex 转换为 只读的内存索引(RO-TempIndex),并将其快照存储到持久化存储。随后创建一个新的空 RW-TempIndex 以接收新的插入点。
API
- Insert(xₚ):将一个新点插入索引中,路由到RW-TempIndex的唯一实例,该实例使用算法2来处理该点。
- Delete(p):删除请求,将已存在的点p添加到DeleteList中。
- Search(xq, K, L):搜索K个最近的候选项,使用大小为L的候选列表,通过查询LTI、RW-TempIndex和所有RO-TempIndex实例来执行,参数为K和L,聚合结果并移除DeleteList中的已删除条目。
StreamingMerge
每当各个RO-TempIndex的总内存占用超过预定的阈值时,系统就会调用一个后台合并过程,修改驻留在SSD上的LTI,以反映来自不同RO-TempIndex实例的插入,并同时处理来自DeleteList的删除请求。为了方便记法,假设数据集P表示LTI中的点,N表示当前阶段的点,它们存在于不同的RO-TempIndex实例中,D表示标记为删除的点。
删除点之后,StreamingMerge的期望结果是一个驻留在SSD上的LTI,数据集为(P ∪ N) \ D。合并过程完成后,系统清除RO-TempIndex实例,从而保持总内存占用在可控范围内。该过程必须遵循以下两个重要约束:
- 内存占用应与变化的大小|D|和|N|成比例,而不是与整个索引|P|的大小成比例。因为LTI的内存占用可能远大于机器的内存。
- 有效使用SSD I/O,以便在后台进行合并时,仍然可以执行搜索操作,这样合并过程本身可以快速完成。
从高层次来看,StreamingMerge首先运行算法4来处理来自D的删除操作,以获得P \ D点的中间LTI索引。然后,StreamingMerge运行算法2,将N中的每个点插入到中间LTI中以获得最终的LTI。然而,算法2和算法4假设LTI图以及所有数据点的全精度向量都存储在内存中。StreamingMerge的关键挑战之一是以内存和SSD高效的方式模拟这些算法调用。该过程分为以下三个阶段:
-
删除阶段:该阶段处理输入的LTI实例,并通过运行算法4处理删除操作D,生成中间LTI。为了以内存高效的方式完成此操作,我们按块从SSD中加载LTI中的点及其邻居,并使用多线程执行算法4来处理块中的节点,然后将修改后的块写回到SSD中的中间LTI。此外,每当算法4或算法3进行距离比较时,我们使用已存储的压缩PQ向量来计算近似距离,而不是使用准确的距离。请注意,这一做法替代了精确的距离计算,通过使用压缩向量来计算近似距离,这将在StreamingMerge的后续阶段中继续使用。
-
插入阶段:该阶段将所有新点N添加到中间LTI中,模拟算法2的过程。作为第一步,我们在SSD驻留的中间LTI上运行GreedySearch(s, p, 1, L)来获取搜索路径上访问的顶点集V。由于图存储在SSD中,任何由搜索算法请求的邻居Nout(p′)都将从SSD中获取。α-RNG属性确保了邻居请求的数量较小,从而保证了每个点的总体延迟是有界的。然后,我们运行RobustPrune(p, V, α, R)程序来确定p的候选邻居集。然而,与算法2不同,我们不会立即尝试将p插入到Nout(p′)中(即反向边),因为这可能导致大量随机的读取和写入操作,从而影响效率。
-
修补阶段:在处理完所有插入后,我们将Δ数据结构修补到输出的SSD驻留LTI索引中。为此,我们按块从SSD中获取中间LTI中的所有点p,添加每个节点p的相关出边,并检查新的度数|Nout(p) ∪ Δ(p)|是否超过R。如果超过,则通过设置Nout(p) = RobustPrune(p, Nout(p) ∪ Δ(p), ·, ·)来修剪邻居。此操作可以以数据并行的方式应用于每个节点。随后,更新后的块将写回到SSD中,之后再加载新的块。
Complexity
- I/O成本:该过程在删除和修补阶段分别对SSD驻留的数据结构进行了两次顺序遍历。由于中间LTI的-RNG属性,插入算法每插入一个点都会执行少量的随机4KB读取(每个插入点大约100次磁盘读取,比候选列表大小参数(我们通常设为75)多一点)。请注意,如果没有-RNG属性,这个数字会大得多,因为可能存在非常长的导航路径。
- 内存占用:在整个StreamingMerge过程中,数据结构的大小为,其中是索引的最大度数,通常是一个较小的常数。例如,如果,且,则内存占用大约为7GB。此外,为了计算近似距离,我们还会保留PQ坐标的副本,用于索引中的所有点(大约32GB用于一个十亿点的索引)。
- 计算需求:插入阶段和修补阶段的复杂度与要插入的新点的大小基本成线性关系,因为插入阶段仅使用算法1对中的新点进行搜索,并更新数据结构;修补阶段则以块为单位添加反向边。
删除阶段的固定成本较小,仅需扫描每个点的,并检查是否有已删除的点,同时存在一个较大的变量成本,与删除集大小成线性关系,我们会将其上界为(假设随机删除)。有关这一计算的详细信息,请参见附录D。
Recall Stability
尽管我们已经证明了我们的更新算法算法2和4在第4.3节中的长时间更新流中确保了召回稳定性,但这些算法在我们StreamingMerge过程中的实际实现形式是不同的,特别是使用了用于距离计算的近似压缩向量。实际上,随着我们处理更多的StreamingMerge过程周期,我们预计初始图将被完全基于近似距离构建的图所替代。因此,我们预计初期会有小幅下降,但随后召回率将稳定。
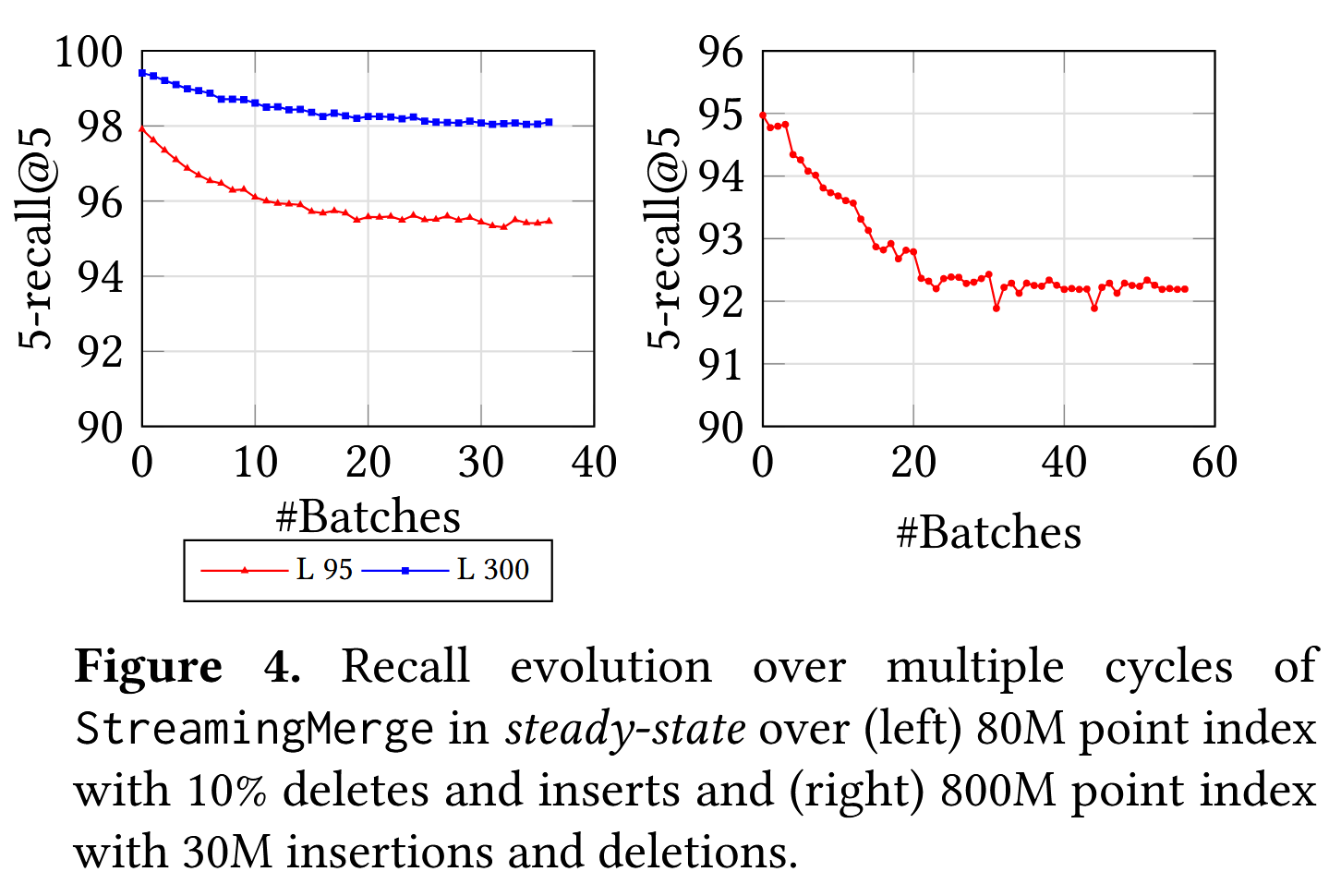
在图4中的实验中,我们首先使用从SIFT100M数据集中随机采样的80M点构建了静态SSD索引。然后,在每个周期中,我们使用StreamingMerge更新索引,以反映8M个删除和来自20M点备用池的等量插入。我们总共运行了40个周期的实验,并在图4中跟踪了每个周期后索引的召回率。请注意,索引的稳定值低于静态索引的初始召回率,这是因为在StreamingMerge过程中使用了近似距离。我们观察到,在删除和插入大约10%索引大小的20个周期后,召回率稳定,此时我们预计大部分图是通过近似距离确定的。图4(右)展示了SIFT1B的800M点子集的相似图。我们已经通过实验证明,FreshDiskANN索引能够在更新流的稳态中保持稳定的召回率。
Crash Recovery
为了支持崩溃恢复,所有索引更新操作都会写入重做日志。当崩溃导致单个RW-TempIndex实例和DeleteList丢失时,它们通过从最近的快照回放重做日志中的更新来重建。由于RO-TempIndex和LTI实例是只读的并且定期快照到磁盘,它们可以简单地从磁盘重新加载。
RW-TempIndex被快照到RO-TempIndex的频率取决于预期的恢复时间。更多的快照会导致RW-TempIndex的重建时间较短,但会创建多个RO-TempIndex实例,所有这些实例必须在每个查询中进行搜索。虽然搜索几个额外的小型内存索引不会成为查询的限制步骤(因为搜索大型LTI很耗时),但是创建太多索引可能导致低效的搜索。对于一个十亿点的索引,通常会在每次合并到LTI之间保留最多30M个点的TempIndex。在内存中限制每个索引为500万个点会导致最多6个TempIndex实例可以在0.77毫秒内完成搜索,相比之下,搜索单个30M大小的索引需要0.89毫秒,且候选列表大小为100。
Filtered − DiskANN: Graph Algorithms for Approximate Nearest Neighbor Search with Filters
FreshDiskANN Introduction
随着基于近似最近邻搜索(ANNS)的稠密检索在搜索和推荐场景中的广泛应用,有效回答过滤后的ANNS查询已成为一个关键需求。过滤后的ANNS查询要求从索引中的点中找到与查询的标签(如日期、价格范围、语言)匹配的最近邻。当前的索引具有较高的搜索延迟或较低的召回率。
本文提出了两种具有原生支持的算法,以便更快速、更准确地回答过滤后的ANNS查询:一种支持流处理,另一种基于批量构建。算法的核心是构建一个图结构索引,该索引不仅基于向量数据的几何形状形成连接,还包括相关的标签集。
大多数当前针对过滤后的 ANNS 方法的共同点是,它们只修改了搜索步骤,而没有修改索引构建步骤。
Drawback of Existing Methods
一种直接的方法来回答混合查询是后处理方法:构建一个标准的 ANNS 索引,像往常一样查询,并通过选择仅那些与查询过滤器匹配的索引返回结果来进行后处理。虽然这种方法容易实现,但在实践中效果不佳。事实上,对于一个低特异性的标签过滤器 f,我们可能需要检索大量候选项才能找到一个符合过滤器的结果。
相反,可以考虑一种简单的预处理方法,即为每个可能的可过滤标签 f ∈ F 构建一个单独的索引,以便将查询路由到与查询过滤器关联的索引。然而,这种方法在过滤器数量庞大或每个点可能有多个关联过滤器的情况下,将很快变得代价高昂。
ANNS 索引需要从 中找到与 最近的邻居,条件是这些邻居的标签与 匹配,即从集合 中选择点。索引应最大化 ,但它是相对于使用集合 计算的真实值,而不是 。在实际使用中通常无法事先确定满足结果的top-k需要多少个候选项,因为中的top-k很有可能大部分都不在 中。
Related Work
已有大量的研究致力于 ANN(近似最近邻搜索)算法的研究 。见最近的基准测试 ,对最先进的 ANN 算法的比较。大多数现有的研究从提高召回率 、规模和成本效率 、分布式索引 、启用实时索引更新 和设计具有理论保证的算法 等角度解决标准的 ANN 问题。随着 ANN 在语义搜索/密集检索中的日益重要的角色,许多应用关键需求在研究文献中未得到充分关注,其中之一就是过滤或过滤查询(这两个术语可互换使用)。
最近有两项关于过滤 ANN 的研究工作。Analytic DB-V ,阿里巴巴的实际系统集成了过滤 ANN 查询,并在 SQL 引擎上进行了优化。它支持并优化了基于查询计划的复杂过滤器,查询计划根据过滤器的特异性来处理:
- 高特异性:后处理索引
- 中等特异性:内联处理 IVF-PQ 索引
- 低特异性:内联处理蛮力索引
在这项工作中,我们限制为更简单的过滤器——与一个过滤器的精确匹配。为了在交互延迟和高召回率下支持此类搜索,我们开发了新的基于图的索引,这些索引可以更新。我们可以通过简单地找到对应每个单独过滤器的答案,并按查询的距离对这些结果进行聚合和排序,轻松扩展到多个过滤器的并(OR)操作。我们将多个过滤器的合取(AND)和其他更复杂的表达式留作未来工作中的挑战。请注意,当可能的谓词集合已知且不太大(几千个)时,我们可以为每个向量标注谓词,以标识它所满足的条件,并构建图来支持通过这些标签进行过滤。
另一个支持过滤查询的近期算法是 NHQ 算法 。它与我们的工作相关,因为它是基于图的,并且实际上修改了索引步骤:它们将过滤器标签编码为向量,并将其附加到真实向量和使用 ANN 算法(如 NSW 或 kNN-graph )的索引中。然而,这篇论文考虑的是每个数据点有效地只与一个过滤器标签相关的情况——即集合 是完全不交集的,这种情况可以通过为每个过滤器分别使用标准的 ANN 索引来处理。此外,这种技术在扩展到多个过滤器/标签时可能会无效,因为每个点的过滤器/标签的数量越多,召回率的显著性影响越大。如果索引中的某一点有三个过滤器标签,而查询只有一个,那么索引中其他两个标签坐标的距离会对候选点产生不利影响,相比之下,只有相同查询标签的数据点将受到更少的影响。我们证明了我们的方法优于 NHQ,并在附录中进一步证明,这比 Analytic DB-V 的表现要好得多。
FilteredVamana
基于图的ANNS索引是这样构造的,使得贪婪搜索能够快速收敛到查询向量 的最近邻。我们首先描述了过滤查询的贪婪搜索的自然适应,称为FilteredGreedySearch(算法1),以及一个索引构建过程(算法4),该过程允许搜索通过相对较少的距离比较收敛到正确的答案。
FilteredGreedySearch
给定一个查询 和一组标签 ,我们要求输出 个近似最近邻,其中输出的每个点至少与 共享一个标签。搜索过程还接收一组起始节点 。对于具有标签集 的查询,集合 通常是 ,其中 是在索引构建期间为标签 计算的指定起始节点。
在本文中,我们基准测试了标签集 是单元素集合的查询,但该算法也可以用于具有 的查询。
该算法维护一个最多包含 个元素的优先队列 。每次迭代时,它会寻找 中最近的未访问邻居 。然后将 添加到已访问节点的集合 中,这是本文稍后引用的一个有用不变式。接着,我们仅将那些从 出发且至少拥有 中一个标签的外邻添加到队列 。最后,如果 ,我们将 截断为包含距离 最近的 个点。搜索在所有 中的节点都已被访问时终止。输出由 中的 个最近邻和已访问节点集合 组成,后者对索引构建有用(但在用户查询中无用)。

Index Construction
起始点选择。我们要求每个过滤器的起始节点满足两个条件:
- 对于带有单一过滤器 的查询,起始点 应与该过滤器相关联,即 ;
- 不应有点在 中作为过多过滤标签的起始点。使用不同过滤器的查询应该跨越许多点来共享,以便我们可以构建一个具有小度数的图,该图适用于所有过滤标签。
实际上,如果一个单一节点作为许多标签的起始点,则从该起始点出发,可能很少有邻接节点带有某个标签,从而导致搜索效果差。我们通过使用算法2中描述的简单随机化负载平衡算法来实现这一点。

增量图构建。FilteredVamana图构建是一个增量算法。我们首先为每个过滤标签识别起始节点 ,并初始化一个空图 。然后,对于每个数据点 ,与之关联的过滤器/标签 ,我们运行FilteredGreedySearch(, , , ),并以集合 为起始点。这将返回一组在搜索中访问到的节点 。所有已访问的节点都具有标签 。
接着,我们通过调用算法3中的过滤感知剪枝过程,以参数 (, , , ) 来修剪候选集 。这确保了图节点对应的 至多有 个外邻。

外邻剪枝,同时消除冗余的近邻向量。剪枝过程依赖于以下原则:对于顶点三元组 ,, 和常数 ,如果满足下列条件,则可以将有向边 从图中剪除:
- 边 存在,
- 向量 比 更接近 ,即 ,
- 包含 和 所有共同的过滤标签,即 。
最后,我们从 到 添加反向边,其中 ,并且,如果任何此类 的度数超过 ,我们在 上运行FilteredRobustPrune过程。

StitchedVamana
我们现在提出一个用于构建索引的不同算法,称为 StitchedVamana(算法 5),该算法只能在已知点集的情况下使用。对于每个 ,我们使用 Vamana 算法 [39] 在带有标签 的点集 上构建图索引 ,其参数为 和 。这些参数比前一个算法中的参数更小,从而加速了索引构建。接下来,由于顶点可能属于多个图(即一个点 可能属于多个 ),我们将各个图 “拼接”到图 中,图 的边是每个 的边集的并集。图 可能会有较大的度数。我们通过使用 FilteredRobustPrune 程序将其最大外度数减少到 。最终的图与 FilteredGreedySearch 程序兼容。

Summary
Comparison of Vamana with HNSW and NSG
Vamana 与 HNSW 和 NSG 非常相似。这三种算法都在数据集 上进行迭代,并使用 GreedySearch(s, , 1, L) 和 RobustPrune(p, , , ) 的结果来确定 的邻居。这些算法之间存在一些重要的差异。
- 最关键的是,HNSW 和 NSG 都没有可调参数 ,而且隐式使用 。(这是使 Vamana 在图的度数和直径之间实现更好折衷的主要因素)
- 虽然 HNSW 将候选集 设置为贪心搜索(GreedySearch(s, , 1, L))的修剪过程的最终候选结果集,Vamana 和 NSG 将 设置为贪心搜索(GreedySearch(s, , 1, L))访问的所有顶点的集合。从直觉上讲,这个特征有助于 Vamana 和 NSG 添加长距离边,而 HNSW 仅通过添加局部边来构建图的层次结构,进而构建嵌套的图序列。
- NSG 将数据集上的图初始化为近似 -最近邻图,这是一个时间和内存密集型的步骤,而 HNSW 和 Vamana 则有更简单的初始化过程,前者从一个空图开始,Vamana 从一个随机图开始。
- Vamana 进行两次遍历数据集,而 HNSW 和 NSG 只进行一次遍历,动机是基于我们观察到的第二次遍历能提高图的质量。
SPANN
SPANN: Highly-efficient Billion-scale Approximate Nearest Neighborhood Search
Faiss
Faiss的使用说明和相关知识。
Composite Indexes
一个复合索引可由以下部分组合而成:
- Vector transform:在索引之前应用于向量的预处理步骤
- PCA:主成分分析,尽可能减少信息损失,将向量投影到低维空间
- OPQ:通过旋转变换优化向量分布,避免信息分布不均匀,以提高量化效果
- Coarse quantizer:用于限制搜索范围
- IVF:
- IMI:
- HNSW:
- Fine quantizer:用于压缩索引大小
- PQ:
- Refinement: 搜索结果排序方式
- RFlat:在原始向量上计算距离
| Vector transform | Coarse quantizer | Fine quantizer | Refinement |
|---|---|---|---|
| PCA, OPQ, RR, L2norm, ITQ, Pad | IVF, Flat, IMI, IVF-HNSW, IVF-PQ, IVF-RCQ, HNSW-Flat, HNSW-SQ, HNSW-PQ | Flat, PQ, SQ, Residual, RQ, LSQ, ZnLattice, LSH | RFlat, Refine* |
Getting Started
全文字数: 1773
阅读时间: 11 minutes
Installing Faiss
# 新建一个干净的环境
conda create -n faiss_env python=3.9 -y
# 切换
conda activate faiss_env
根据需要安装CPU或GPU版本的Faiss
# CPU-only version
conda install -c pytorch faiss-cpu=1.10.0
# GPU(+CPU) version
conda install -c pytorch -c nvidia faiss-gpu=1.10.0
# GPU(+CPU) version with NVIDIA cuVS
conda install -c pytorch -c nvidia -c rapidsai -c conda-forge libnvjitlink faiss-gpu-cuvs=1.10.0
# GPU(+CPU) version using AMD ROCm not yet available
Basic Usage
import numpy as np
d = 64 # dimension
nb = 100000 # database size
nq = 10000 # nb of queries
np.random.seed(1234) # make reproducible
xb = np.random.random((nb, d)).astype('float32')
xb[:, 0] += np.arange(nb) / 1000.
xq = np.random.random((nq, d)).astype('float32')
xq[:, 0] += np.arange(nq) / 1000.
import faiss # make faiss available
index = faiss.IndexFlatL2(d) # build the index
print(index.is_trained)
index.add(xb) # add vectors to the index
print(index.ntotal)
k = 4 # we want to see 4 nearest neighbors
D, I = index.search(xb[:5], k) # sanity check
print(I)
print(D)
D, I = index.search(xq, k) # actual search
print(I[:5]) # neighbors of the 5 first queries
print(I[-5:]) # neighbors of the 5 last queries
Getting some data
import numpy as np
d = 64 # dimension
nb = 100000 # database size
nq = 10000 # nb of queries
np.random.seed(1234) # make reproducible
xb = np.random.random((nb, d)).astype('float32')
xb[:, 0] += np.arange(nb) / 1000.
xq = np.random.random((nq, d)).astype('float32')
xq[:, 0] += np.arange(nq) / 1000.
d:向量的维度nb:数据库的大小nq:查询的数量xb:数据库向量xq:查询向量
xb[:, 0] += np.arange(nb) / 1000.:构造具有一定分布规律的数据,使与i号查询相近的向量就在数据库中i号附近。
Building an index and adding the vectors to it
import faiss # make faiss available
index = faiss.IndexFlatL2(d) # build the index
print(index.is_trained)
index.add(xb) # add vectors to the index
print(index.ntotal)
Faiss 是围绕 Index 对象构建的。它封装数据库向量集,并选择性地对它们进行预处理以提高搜索效率。
所有索引在构建时都需要知道它们操作的向量的维度。大多数索引还需要一个训练阶段,以分析向量的分布。对于 IndexFlatL2可以跳过这个操作。
当索引构建并训练完成后,可以对索引执行两个操作:add 和 search 。
要向索引中添加元素,调用 add 并传入 xb。还可以查看索引的两个状态变量:is_trained(指示是否需要训练)和 ntotal(索引中存储的向量数量)。
Searching
k = 4 # we want to see 4 nearest neighbors
D, I = index.search(xb[:5], k) # sanity check
print(I)
print(D)
D, I = index.search(xq, k) # actual search
print(I[:5]) # neighbors of the 5 first queries
print(I[-5:]) # neighbors of the 5 last queries
为了检查正确性,可以先搜索数据库中的前5个向量,查看其最近邻居是否是自身。
[[ 0 393 363 78]
[ 1 555 277 364]
[ 2 304 101 13]
[ 3 173 18 182]
[ 4 288 370 531]]
[[ 0. 7.17517328 7.2076292 7.25116253]
[ 0. 6.32356453 6.6845808 6.79994535]
[ 0. 5.79640865 6.39173603 7.28151226]
[ 0. 7.27790546 7.52798653 7.66284657]
[ 0. 6.76380348 7.29512024 7.36881447]]
实际搜索输出的结果类似于
[[ 381 207 210 477]
[ 526 911 142 72]
[ 838 527 1290 425]
[ 196 184 164 359]
[ 526 377 120 425]]
[[ 9900 10500 9309 9831]
[11055 10895 10812 11321]
[11353 11103 10164 9787]
[10571 10664 10632 9638]
[ 9628 9554 10036 9582]]
由于向量的第一个分量增加了附加值,数据集在 d 维空间的第一轴上被扩散。所以,前几个向量的邻居位于数据集的开头,而大约在 10000 附近的向量的邻居也在数据集的 10000 索引附近。
Faster search (IVF)
...
import faiss
nlist = 100
k = 4
quantizer = faiss.IndexFlatL2(d) # the other index
# here we specify METRIC_L2, by default it performs inner-product search
index = faiss.IndexIVFFlat(quantizer, d, nlist, faiss.METRIC_L2)
index.train(xb)
index.add(xb) # add may be a bit slower as well
D, I = index.search(xq, k) # actual search
print(I[-5:]) # neighbors of the 5 last queries
index.nprobe = 10 # default nprobe is 1, try a few more
D, I = index.search(xq, k)
print(I[-5:]) # neighbors of the 5 last queries
为了加快搜索速度,可以将数据集划分为多个片段。在 维空间中定义 Voronoi cells,每个数据库向量都会归属于其中一个细胞。
在搜索时,仅比较查询向量 所落入的细胞及其附近的一些相邻细胞中的数据库向量 。
这一过程是通过 IndexIVFFlat 索引实现的。这种类型的索引需要一个训练阶段,该阶段可以在与数据库向量具有相同分布的任何向量集合上执行。在本例中,我们直接使用数据库向量进行训练。
IndexIVFFlat 还需要一个额外的索引,即 quantizer,用于将向量分配到 Voronoi 细胞中。每个细胞由一个centroid定义,确定一个向量属于哪个 Voronoi 细胞的过程,本质上是找到该向量在所有中心点中的最近邻居。这个任务通常由IndexFlatL2索引来完成。
搜索方法有两个关键参数:
- nlist:细胞的总数。
- nprobe:搜索时访问的细胞数量。
搜索时间大致与探测的细胞数量成线性关系,同时还会有一部分由量化过程带来的额外开销。
当nprobe=1时,结果类似于:
[[ 9900 10500 9831 10808]
[11055 10812 11321 10260]
[11353 10164 10719 11013]
[10571 10203 10793 10952]
[ 9582 10304 9622 9229]]
当nprobe=10时,结果类似于:
[[ 9900 10500 9309 9831]
[11055 10895 10812 11321]
[11353 11103 10164 9787]
[10571 10664 10632 9638]
[ 9628 9554 10036 9582]]
得到了正确的结果。但是获得完美的结果只是因为该数据有很规律的分布,它在 x 轴上具有很强的分量,这使得它更容易处理。该参数始终是调整结果的速度和准确性之间的权衡的一种方式。设置 nprobe = nlist 给出的结果与暴力搜索相同。
Lower memory footprint (PQ)
...
nlist = 100
m = 8
k = 4
quantizer = faiss.IndexFlatL2(d) # this remains the same
# 8 specifies that each sub-vector is encoded as 8 bits
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8)
index.train(xb)
index.add(xb)
D, I = index.search(xb[:5], k) # sanity check
print(I)
print(D)
index.nprobe = 10 # make comparable with experiment above
D, I = index.search(xq, k) # search
print(I[-5:])
之前看到的索引,IndexFlatL2 和 IndexIVFFlat,都会存储完整的向量。为了扩展到非常大的数据集,Faiss 提供了基于**乘积量化(Product Quantizer)**的有损压缩变体,以压缩存储的向量。
这些向量仍然存储在Voronoi 单元中,但其大小被减少到可配置的字节数 m(维度 d 必须是 m 的倍数)。
由于向量并不是以完全精确的形式存储的,因此搜索方法返回的距离值也是近似的。
运行结果如下:
[[ 0 608 220 228]
[ 1 1063 277 617]
[ 2 46 114 304]
[ 3 791 527 316]
[ 4 159 288 393]]
[[ 1.40704751 6.19361687 6.34912491 6.35771513]
[ 1.49901485 5.66632462 5.94188499 6.29570007]
[ 1.63260388 6.04126883 6.18447495 6.26815748]
[ 1.5356375 6.33165455 6.64519501 6.86594009]
[ 1.46203303 6.5022912 6.62621975 6.63154221]]
可以看到最近邻被正确找到(即向量本身),但向量与自身的估算距离并不为 0(明显小于它与其他邻居的距离),这是由于有损压缩导致的。
这里将64 个 32 位浮点数压缩到8 字节,压缩比为32。
Simplifying index construction
构建索引可能会变得复杂,Faiss 提供了工厂函数根据字符串来构造索引。
index = faiss.index_factory(d, "IVF100,PQ8")
将 PQ8 替换为 Flat,即可获得 IndexFlat。当对输入向量进行**预处理(如 PCA)**时,工厂函数特别有用。例如,使用字符串 "PCA32,IVF100,Flat" 可以通过 PCA 投影将向量维度降至 32D。
Basics
全文字数: 1556
阅读时间: 9 minutes
MetricType and distances
METRIC_L2
平方欧几里得(L2)距离(由于平方根是单调的,没有做平方根运算),此度量对数据的旋转不变(正交矩阵变换)。
METRIC_INNER_PRODUCT
查询向量的范数不会影响结果的排名(数据库向量的范数确实重要)。其本身不是余弦相似度,除非向量已经归一化。
**如何对余弦相似度进行向量索引?**向量x和y之间的余弦相似度定义为:
它是相似度,而不是距离,因此通常会搜索相似度较大的向量。
通过预先归一化查询和数据库向量,可以将问题映射回最大内积搜索。执行此操作的方法:
- 使用METRIC_INNER_PRODUCT构建索引
- 在将向量添加到索引之前先归一化向量(在Python中使用faiss.normalize_L2)
- 在搜索之前先归一化向量
Clustering, PCA, Quantization
Faiss 具有非常高效的k-means 聚类、PCA、PQ 编解码实现:。
Clustering
Faiss 提供了一个高效的 k-means 实现。将存储在给定 2D 张量 中的一组向量进行聚类,操作如下:
ncentroids = 1024
niter = 20
verbose = True
d = x.shape[1]
kmeans = faiss.Kmeans(d, ncentroids, niter=niter, verbose=verbose)
kmeans.train(x)
最终的质心保存在 kmeans.centroids 中。
目标函数的值(在 k-means 中是总平方误差)在每次迭代中的变化存储在变量 kmeans.obj 中,更详细的统计信息存储在 kmeans.iteration_stats 中。
要在 GPU 上运行,在 Kmeans 构造函数中添加选项 gpu=True。(使用所有 GPU)或 gpu=3(使用 3 个 GPU)。
Kmeans 对象主要是 C++ 中 Clustering 对象的一层,所有该对象的字段可以通过构造函数进行设置。字段包括:
nredo:运行聚类的次数,并保留最佳质心(根据聚类目标选择)verbose:使聚类过程更加详细spherical:执行球形 k-means —— 每次迭代后,质心会进行 L2 归一化int_centroids:将质心坐标四舍五入为整数update_index:每次迭代后是否重新训练索引?min_points_per_centroid/max_points_per_centroid:收到警告,表示训练集已被子采样seed:随机数生成器的种子
Asignment
要计算从一组向量 到聚类质心的映射,在 k-means 训练完成后,可以使用:
D, I = kmeans.index.search(x, 1)
将返回 中每个行向量的最近质心, 包含这些质心的索引, 包含平方的 L2 距离。
对于反向操作,例如查找 中距离已计算质心最近的 15 个点,必须使用新的索引:
index = faiss.IndexFlatL2(d)
index.add(x)
D, I = index.search(kmeans.centroids, 15)
其中,大小为 的 包含每个质心的最近邻。
PCA
将 40D 向量降维到 10D。
# 随机训练数据
mt = np.random.rand(1000, 40).astype('float32')
mat = faiss.PCAMatrix(40, 10)
mat.train(mt)
assert mat.is_trained
tr = mat.apply(mt)
# 打印此结果以展示 tr 的列的幅度在减少
print((tr ** 2).sum())
Quantizers
量化器对象继承自 Quantizer,提供了三种常见的方法(见 impl/Quantizer.h):
- train:在一组向量矩阵上训练量化器。
- compute_codes 和 decode:编码器和解码器。编码器通常是有损的,并返回每个输入向量的 uint8 类型代码矩阵。
- get_DistanceComputer:这是一个返回 DistanceComputer 对象的方法。
Quantizer 对象的状态是训练的结果(代码书表或归一化系数)。字段 code_size 表示量化器生成的每个代码的字节数。
支持的量化器类型有:
- ScalarQuantizer:将每个向量分量单独量化为线性范围内的值。
- ProductQuantizer:对子向量进行向量量化。
- AdditiveQuantizer:将一个向量编码为代码书条目的和,详情见 Additive Quantizers。Additive 量化器可以通过多种方式进行训练,因此有子类 ResidualQuantizer、LocalSearchQuantizer 和 ProductAdditiveQuantizer。
有趣的是,每个量化器都是前一个量化器的超集。
每个量化器都有一个对应的索引类型,它还存储一组量化向量。
| 量化器类 | 平面索引类 | IVF 索引类 |
|---|---|---|
| ScalarQuantizer | IndexScalarQuantizer | IndexIVFScalarQuantizer |
| ProductQuantizer | IndexPQ | IndexIVFPQ |
| AdditiveQuantizer | IndexAdditiveQuantizer | IndexIVFAdditiveQuantizer |
| ResidualQuantizer | IndexResidualQuantizer | IndexIVFResidualQuantizer |
| LocalSearchQuantizer | IndexLocalSearchQuantizer | IndexIVFLocalSearchQuantizer |
另外,除了 ScalarQuantizer 的索引,所有索引都有 FastScan 版本
一些量化器返回一个 DistanceComputer 对象。它的目的是在一个向量与许多代码进行比较时,高效地计算向量与代码之间的距离。在这种情况下,通常可以预先计算一组表,以便在压缩域中直接计算距离。
因此,DistanceComputer 提供以下方法:
- set_query:设置当前未压缩的向量进行比较。
- distance_to_code:计算与给定代码的实际距离。
ProductQuantizer 对象可用于将向量编码或解码为代码:
d = 32 # 数据维度
cs = 4 # 代码大小(字节)
# 训练集
nt = 10000
xt = np.random.rand(nt, d).astype('float32')
# 编码数据集(可以与训练集相同)
n = 20000
x = np.random.rand(n, d).astype('float32')
pq = faiss.ProductQuantizer(d, cs, 8)
pq.train(xt)
# 编码
codes = pq.compute_codes(x)
# 解码
x2 = pq.decode(codes)
# 计算重建误差
avg_relative_error = ((x - x2)**2).sum() / (x ** 2).sum()
标量量化器的工作方式类似:
d = 32 # 数据维度
# 训练集
nt = 10000
xt = np.random.rand(nt, d).astype('float32')
# 编码数据集(可以与训练集相同)
n = 20000
x = np.random.rand(n, d).astype('float32')
# QT_8bit 为每个维度分配 8 位(QT_4bit 也可以使用)
sq = faiss.ScalarQuantizer(d, faiss.ScalarQuantizer.QT_8bit)
sq.train(xt)
# 编码
codes = sq.compute_codes(x)
# 解码
x2 = sq.decode(codes)
# 计算重建误差
avg_relative_error = ((x - x2)**2).sum() / (x ** 2).sum()
Guidelines to choose an index
- 少量搜索?
- 只进行少量搜索(例如 1000-10000 次),那么索引构建时间将无法通过搜索时间来摊销。此时,直接计算是最有效的选择。通过 "Flat" 索引来完成的。如果整个数据集无法放入 RAM 中,可以一个接一个地构建小的索引,并组合搜索结果。
- 需要精确的结果?
- 唯一可以保证精确结果的索引是 IndexFlatL2 或 IndexFlatIP。它为其他索引提供了结果的基准。它不支持
add_with_ids,只支持顺序添加.
- 唯一可以保证精确结果的索引是 IndexFlatL2 或 IndexFlatIP。它为其他索引提供了结果的基准。它不支持
Project
Faiss
bench
HNSW
faiss/benchs/bench_hnsw.py
本程序用于对比不同索引算法在 SIFT1M 数据集上的性能表现,帮助用户评估搜索速度与准确率。测试方法包括 HNSW、IVF 等多种常见索引类型。
使用步骤
-
基本命令格式
python 程序名.py [k值] [测试方法1] [测试方法2]... -
参数说明
- k值 (必需): 指定每个查询要返回的最近邻数量
- 测试方法 (可选): 指定要运行的算法测试,支持以下选项:
- hnsw (HNSW 平面索引)
- hnsw_sq (量化HNSW)
- ivf (IVF 平面索引)
- ivf_hnsw_quantizer (HNSW量化的IVF)
- kmeans (K均值基准测试)
- kmeans_hnsw (HNSW辅助的K均值)
- nsg (NSG 图索引)
若不指定测试方法,默认运行所有测试
-
运行示例
# 返回10个最近邻,测试HNSW和IVF python demo.py 10 hnsw ivf # 返回5个最近邻,测试所有方法 python demo.py 5 -
输出说明 程序运行后会显示每个测试方法的以下指标:
- ms per query: 每个查询的平均耗时(毫秒)
- R@1: 前1个结果的召回率(准确率)
- missing rate: 无效结果比例(-1表示未找到)
示例输出:
Testing HNSW Flat add... search... efSearch 16 bounded_queue True 0.153 ms per query, R@1 0.9210, missing rate 0.0000 efSearch 16 bounded_queue False 0.162 ms per query, R@1 0.9210, missing rate 0.0000 ...
在代码中,missing rate 是通过以下方式计算的:
missing_rate = (I == -1).sum() / float(k * nq)
I: 是搜索结果的索引矩阵,形状为(nq, k),其中nq是查询的数量,k是每个查询返回的最近邻数量。- 如果某个查询的某个最近邻未被找到,
I中对应的值会被设置为-1。
- 如果某个查询的某个最近邻未被找到,
(I == -1).sum(): 统计所有查询结果中未找到的最近邻数量(即I中值为-1的元素总数)。k * nq: 表示理论上应该返回的总结果数量(每个查询返回k个结果,共有nq个查询)。missing_rate: 未找到的结果占总结果的比例。
直观上看,missing rate表现了要搜索k个最近邻但是并没有找到那么多的最近邻的情况。
运行结果
以下是对实验结果的详细分析,按测试方法分类总结性能指标(搜索速度、召回率、缺失率)和参数影响:
HNSW Flat (分层可导航小世界图)
| efSearch | Bounded Queue | 耗时/查询 | R@1 | 缺失率 |
|---|---|---|---|---|
| 16 | True | 0.006ms | 0.9125 | 0% |
| 16 | False | 0.006ms | 0.9124 | 0% |
| 32 | True | 0.010ms | 0.9620 | 0% |
| 32 | False | 0.010ms | 0.9620 | 0% |
| 64 | True | 0.017ms | 0.9868 | 0% |
| 128 | True | 0.029ms | 0.9966 | 0% |
| 256 | True | 0.055ms | 0.9992 | 0% |
- 速度与召回率的权衡:
efSearch增大时,召回率显著提升(从 0.9125 到 0.9992),但搜索耗时线性增加(从 0.006ms 到 0.055ms)。- 推荐参数:
- 高精度场景:
efSearch=256(R@1=99.92%),耗时 0.055ms/查询。 - 平衡场景:
efSearch=64(R@1=98.68%),耗时 0.017ms/查询。
- 高精度场景:
- Bounded Queue 影响:
- Bounded Queue 开启与否对召回率和速度几乎无影响,可默认开启以节省内存。
HNSW with Scalar Quantizer (标量量化)
| efSearch | 耗时/查询 | R@1 | 缺失率 |
|---|---|---|---|
| 16 | 0.002ms | 0.7993 | 0% |
| 32 | 0.003ms | 0.8877 | 0% |
| 64 | 0.006ms | 0.9453 | 0% |
| 128 | 0.010ms | 0.9780 | 0% |
| 256 | 0.017ms | 0.9932 | 0% |
- 量化对性能的影响:
- 相比 HNSW Flat,量化后搜索速度更快(
efSearch=256时 0.017ms vs 0.055ms),但召回率下降(99.32% vs 99.92%)。 - 适用场景:
- 内存敏感场景:量化可减少内存占用,但需接受轻微精度损失。
- 相比 HNSW Flat,量化后搜索速度更快(
- 参数选择:
- 若需接近原始精度,选择
efSearch=256(R@1=99.32%)。
- 若需接近原始精度,选择
IVF Flat (倒排文件索引)
| nprobe | 耗时/查询 | R@1 | 缺失率 |
|---|---|---|---|
| 1 | 0.004ms | 0.4139 | 3.0% |
| 4 | 0.005ms | 0.6368 | 0% |
| 16 | 0.014ms | 0.8322 | 0% |
| 64 | 0.046ms | 0.9562 | 0% |
| 256 | 0.132ms | 0.9961 | 0% |
- nprobe 的重要性:
nprobe=1时缺失率 3%,召回率仅 41.39%,表明搜索覆盖的聚类中心不足。nprobe=16时召回率 83.22%,耗时 0.014ms,性价比最高。
- 与 HNSW 对比:
- 相同召回率下(如 99%),IVF 耗时更高(0.132ms vs HNSW 的 0.055ms)。
IVF with HNSW Quantizer
| nprobe | 耗时/查询 | R@1 | 缺失率 |
|---|---|---|---|
| 1 | 0.003ms | 0.4095 | 3.16% |
| 4 | 0.005ms | 0.6324 | 0% |
| 16 | 0.013ms | 0.8291 | 0% |
| 64 | 0.041ms | 0.9540 | 0% |
| 256 | 0.136ms | 0.9922 | 0% |
- HNSW Quantizer 的影响:
- 性能与传统 IVF 几乎一致,但训练速度可能更快(代码中未展示具体时间)。
- 仍需设置
nprobe≥16以避免高缺失率。
KMeans 聚类测试
-
Baseline KMeans:
- 目标函数值
3.8508e+10,聚类不均衡度1.227。
- 目标函数值
-
HNSW-Assisted KMeans:
- 目标函数值略高(
3.85126e+10),但训练时间显著减少(24.75s vs 53.52s)。
- 目标函数值略高(
-
HNSW 加速效果:
- HNSW 辅助的 KMeans 将训练时间减少 50%+,适合大规模数据聚类。
NSG (导航小世界图)
| search_L | 耗时/查询 | R@1 | 缺失率 |
|---|---|---|---|
| -1 | 0.004ms | 0.8150 | 0% |
| 16 | 0.006ms | 0.8852 | 0% |
| 32 | 0.009ms | 0.9533 | 0% |
| 64 | 0.015ms | 0.9832 | 0% |
| 128 | 0.027ms | 0.9959 | 0% |
| 256 | 0.050ms | 0.9994 | 0% |
- search_L 的影响:
search_L=256时召回率 99.94%,与 HNSW Flat(99.92%)相当,但耗时稍高(0.050ms vs 0.055ms)。- 优势:NSG 在中等参数下(如
search_L=64)即可达到 98.32% 召回率,适合对精度和速度均衡要求较高的场景。
综合对比与推荐
| 索引类型 | 最佳参数 | 耗时/查询 | R@1 | 适用场景 |
|---|---|---|---|---|
| HNSW Flat | efSearch=64 | 0.017ms | 98.68% | 高精度实时搜索 |
| HNSW SQ | efSearch=256 | 0.017ms | 99.32% | 内存敏感场景 |
| IVF Flat | nprobe=64 | 0.046ms | 95.62% | 高吞吐量批量查询 |
| NSG | search_L=64 | 0.015ms | 98.32% | 均衡精度与速度 |
| IVF+HNSQ Quant | nprobe=64 | 0.041ms | 95.40% | 需要快速训练的 IVF 场景 |
- 精度优先:选择 HNSW Flat(efSearch=256) 或 NSG(search_L=256)。
- 速度优先:选择 HNSW SQ(efSearch=16) 或 IVF Flat(nprobe=16)。
- 内存敏感:使用 HNSW SQ 或 IVF 索引。
- 训练时间敏感:尝试 HNSW-Assisted KMeans 加速聚类。
实验输出
实验输出
(faiss_env) gpu@gpu-node:~/faiss/faiss/benchs$ python bench_hnsw.py 10
load data
Testing HNSW Flat
add
hnsw_add_vertices: adding 1000000 elements on top of 0 (preset_levels=0)
max_level = 4
Adding 1 elements at level 4
Adding 26 elements at level 3
Adding 951 elements at level 2
Adding 30276 elements at level 1
Adding 968746 elements at level 0
Done in 10194.740 ms
search
efSearch 16 bounded queue True 0.006 ms per query, R@1 0.9125, missing rate 0.0000
efSearch 16 bounded queue False 0.006 ms per query, R@1 0.9124, missing rate 0.0000
efSearch 32 bounded queue True 0.010 ms per query, R@1 0.9620, missing rate 0.0000
efSearch 32 bounded queue False 0.010 ms per query, R@1 0.9620, missing rate 0.0000
efSearch 64 bounded queue True 0.017 ms per query, R@1 0.9868, missing rate 0.0000
efSearch 64 bounded queue False 0.017 ms per query, R@1 0.9868, missing rate 0.0000
efSearch 128 bounded queue True 0.029 ms per query, R@1 0.9966, missing rate 0.0000
efSearch 128 bounded queue False 0.030 ms per query, R@1 0.9966, missing rate 0.0000
efSearch 256 bounded queue True 0.055 ms per query, R@1 0.9992, missing rate 0.0000
efSearch 256 bounded queue False 0.055 ms per query, R@1 0.9992, missing rate 0.0000
Testing HNSW with a scalar quantizer
training
add
hnsw_add_vertices: adding 1000000 elements on top of 0 (preset_levels=0)
max_level = 5
Adding 1 elements at level 5
Adding 15 elements at level 4
Adding 194 elements at level 3
Adding 3693 elements at level 2
Adding 58500 elements at level 1
Adding 937597 elements at level 0
Done in 3322.349 ms
search
efSearch 16 0.002 ms per query, R@1 0.7993, missing rate 0.0000
efSearch 32 0.003 ms per query, R@1 0.8877, missing rate 0.0000
efSearch 64 0.006 ms per query, R@1 0.9453, missing rate 0.0000
efSearch 128 0.010 ms per query, R@1 0.9780, missing rate 0.0000
efSearch 256 0.017 ms per query, R@1 0.9932, missing rate 0.0000
Testing IVF Flat (baseline)
training
Training level-1 quantizer
Training level-1 quantizer on 100000 vectors in 128D
Training IVF residual
IndexIVF: no residual training
add
IndexIVFFlat::add_core: added 1000000 / 1000000 vectors
search
nprobe 1 0.004 ms per query, R@1 0.4139, missing rate 0.0300
nprobe 4 0.005 ms per query, R@1 0.6368, missing rate 0.0000
nprobe 16 0.014 ms per query, R@1 0.8322, missing rate 0.0000
nprobe 64 0.046 ms per query, R@1 0.9562, missing rate 0.0000
nprobe 256 0.132 ms per query, R@1 0.9961, missing rate 0.0000
Testing IVF Flat with HNSW quantizer
training
Training level-1 quantizer
Training L2 quantizer on 100000 vectors in 128D
Adding centroids to quantizer
Training IVF residual
IndexIVF: no residual training
add
IndexIVFFlat::add_core: added 1000000 / 1000000 vectors
search
nprobe 1 0.003 ms per query, R@1 0.4095, missing rate 0.0316
nprobe 4 0.005 ms per query, R@1 0.6324, missing rate 0.0000
nprobe 16 0.013 ms per query, R@1 0.8291, missing rate 0.0000
nprobe 64 0.041 ms per query, R@1 0.9540, missing rate 0.0000
nprobe 256 0.136 ms per query, R@1 0.9922, missing rate 0.0000
Performing kmeans on sift1M database vectors (baseline)
Clustering 1000000 points in 128D to 16384 clusters, redo 1 times, 10 iterations
Preprocessing in 0.15 s
Iteration 9 (53.52 s, search 53.23 s): objective=3.8508e+10 imbalance=1.227 nsplit=0
Performing kmeans on sift1M using HNSW assignment
Clustering 1000000 points in 128D to 16384 clusters, redo 1 times, 10 iterations
Preprocessing in 0.15 s
Iteration 9 (24.75 s, search 24.04 s): objective=3.85126e+10 imbalance=1.227 nsplit=0
Testing NSG Flat
add
IndexNSG::add 1000000 vectors
Build knn graph with NNdescent S=10 R=100 L=114 niter=10
Parameters: K=64, S=10, R=100, L=114, iter=10
Iter: 0, recall@64: 0.000000
Iter: 1, recall@64: 0.002813
Iter: 2, recall@64: 0.024688
Iter: 3, recall@64: 0.117656
Iter: 4, recall@64: 0.334219
Iter: 5, recall@64: 0.579063
Iter: 6, recall@64: 0.759375
Iter: 7, recall@64: 0.867188
Iter: 8, recall@64: 0.928594
Iter: 9, recall@64: 0.959063
Added 1000000 points into the index
Check the knn graph
nsg building
NSG::build R=32, L=64, C=132
Degree Statistics: Max = 32, Min = 1, Avg = 20.055180
Attached nodes: 0
search
search_L -1 0.004 ms per query, R@1 0.8150, missing rate 0.0000
search_L 16 0.006 ms per query, R@1 0.8852, missing rate 0.0000
search_L 32 0.009 ms per query, R@1 0.9533, missing rate 0.0000
search_L 64 0.015 ms per query, R@1 0.9832, missing rate 0.0000
search_L 128 0.027 ms per query, R@1 0.9959, missing rate 0.0000
search_L 256 0.050 ms per query, R@1 0.9994, missing rate 0.0000
运行结果(WSL)
HNSW Flat 性能
| 参数 | 构建时间 (ms) | 搜索时间 (ms/query) | R@1 | 缺失率 |
|---|---|---|---|---|
| efSearch=16 (bounded) | 28,095.8 | 0.015 | 0.9069 | 0.0000 |
| efSearch=16 (unbounded) | 28,095.8 | 0.015 | 0.9069 | 0.0000 |
| efSearch=32 (bounded) | 28,095.8 | 0.023 | 0.9614 | 0.0000 |
| efSearch=32 (unbounded) | 28,095.8 | 0.025 | 0.9614 | 0.0000 |
| efSearch=64 (bounded) | 28,095.8 | 0.043 | 0.9868 | 0.0000 |
| efSearch=64 (unbounded) | 28,095.8 | 0.041 | 0.9868 | 0.0000 |
| efSearch=128 (bounded) | 28,095.8 | 0.069 | 0.9964 | 0.0000 |
| efSearch=256 (bounded) | 28,095.8 | 0.126 | 0.9995 | 0.0000 |
- 搜索效率与召回率正相关:
efSearch值越大,搜索时间增加,但召回率显著提升(如efSearch=256时 R@1 达 0.9995)。 - 队列类型影响小:
bounded与unbounded队列对搜索性能无明显差异。
HNSW 标量量化(SQ)性能
| 参数 | 构建时间 (ms) | 搜索时间 (ms/query) | R@1 | 缺失率 |
|---|---|---|---|---|
| efSearch=16 | 12,376.8 | 0.007 | 0.7884 | 0.0000 |
| efSearch=32 | 12,376.8 | 0.011 | 0.8827 | 0.0000 |
| efSearch=64 | 12,376.8 | 0.020 | 0.9419 | 0.0000 |
| efSearch=128 | 12,376.8 | 0.033 | 0.9751 | 0.0000 |
| efSearch=256 | 12,376.8 | 0.055 | 0.9912 | 0.0000 |
- 量化显著加速构建:构建时间缩短至 12,376.8 ms(相比 HNSW Flat 的 28,095.8 ms)。
- 召回率略降:相同
efSearch下,量化后 R@1 低于原始 HNSW(如efSearch=256时 R@1=0.9912 vs. 0.9995)。
IVF Flat 基准性能
| 参数 | 搜索时间 (ms/query) | R@1 | 缺失率 |
|---|---|---|---|
| nprobe=1 | 0.022 | 0.4139 | 0.0300 |
| nprobe=4 | 0.018 | 0.6368 | 0.0000 |
| nprobe=16 | 0.035 | 0.8322 | 0.0000 |
| nprobe=64 | 0.103 | 0.9562 | 0.0000 |
| nprobe=256 | 0.332 | 0.9961 | 0.0000 |
- 需高
nprobe保证召回率:nprobe=256时 R@1 接近 HNSW,但搜索时间显著增加(0.332 ms vs. HNSW 的 0.126 ms)。
NSG Flat 性能
| 参数 | 搜索时间 (ms/query) | R@1 | 缺失率 |
|---|---|---|---|
| search_L=-1 | 0.008 | 0.8152 | 0.0000 |
| search_L=16 | 0.011 | 0.8849 | 0.0000 |
| search_L=32 | 0.017 | 0.9528 | 0.0000 |
| search_L=64 | 0.032 | 0.9843 | 0.0000 |
| search_L=128 | 0.051 | 0.9959 | 0.0000 |
| search_L=256 | 0.086 | 0.9993 | 0.0000 |
- 高效搜索与高召回率:在
search_L=256时,R@1 达 0.9993,且搜索时间(0.086 ms)优于 HNSW Flat 的 0.126 ms。
综合对比
| 索引类型 | 构建时间 (ms) | 最佳 R@1 | 对应搜索时间 (ms) |
|---|---|---|---|
| HNSW Flat | 28,095.8 | 0.9995 | 0.126 |
| HNSW SQ | 12,376.8 | 0.9912 | 0.055 |
| IVF Flat | - | 0.9961 | 0.332 |
| NSG Flat | - | 0.9993 | 0.086 |
- HNSW 系列:
- 适合高召回率场景,但构建时间较长;量化版本(HNSW SQ)可显著加速构建,但牺牲少量召回率。
- IVF Flat:
- 需要高
nprobe达到高召回率,但搜索效率较低。
- 需要高
- NSG Flat:
- 在搜索速度与召回率间取得最佳平衡(
search_L=256时 R@1=0.9993,搜索时间仅 0.086 ms)。
- 在搜索速度与召回率间取得最佳平衡(
- 实时搜索:优先选择 HNSW SQ 或 NSG Flat;
- 高精度需求:选择 HNSW Flat 或 NSG Flat;
- 快速构建:选择 HNSW SQ。
实验输出
实验输出
(faiss_env) root@Quaternijkon:~/faiss/benchs# python bench_hnsw.py 10
load data
Testing HNSW Flat
add
hnsw_add_vertices: adding 1000000 elements on top of 0 (preset_levels=0)
max_level = 4
Adding 1 elements at level 4
Adding 26 elements at level 3
Adding 951 elements at level 2
Adding 30276 elements at level 1
Adding 968746 elements at level 0
Done in 28095.800 ms
search
efSearch 16 bounded queue True 0.015 ms per query, R@1 0.9069, missing rate 0.0000
efSearch 16 bounded queue False 0.015 ms per query, R@1 0.9069, missing rate 0.0000
efSearch 32 bounded queue True 0.023 ms per query, R@1 0.9614, missing rate 0.0000
efSearch 32 bounded queue False 0.025 ms per query, R@1 0.9614, missing rate 0.0000
efSearch 64 bounded queue True 0.043 ms per query, R@1 0.9868, missing rate 0.0000
efSearch 64 bounded queue False 0.041 ms per query, R@1 0.9868, missing rate 0.0000
efSearch 128 bounded queue True 0.069 ms per query, R@1 0.9964, missing rate 0.0000
efSearch 128 bounded queue False 0.069 ms per query, R@1 0.9964, missing rate 0.0000
efSearch 256 bounded queue True 0.126 ms per query, R@1 0.9995, missing rate 0.0000
efSearch 256 bounded queue False 0.122 ms per query, R@1 0.9995, missing rate 0.0000
Testing HNSW with a scalar quantizer
training
add
hnsw_add_vertices: adding 1000000 elements on top of 0 (preset_levels=0)
max_level = 5
Adding 1 elements at level 5
Adding 15 elements at level 4
Adding 194 elements at level 3
Adding 3693 elements at level 2
Adding 58500 elements at level 1
Adding 937597 elements at level 0
Done in 12376.822 ms
search
efSearch 16 0.007 ms per query, R@1 0.7884, missing rate 0.0000
efSearch 32 0.011 ms per query, R@1 0.8827, missing rate 0.0000
efSearch 64 0.020 ms per query, R@1 0.9419, missing rate 0.0000
efSearch 128 0.033 ms per query, R@1 0.9751, missing rate 0.0000
efSearch 256 0.055 ms per query, R@1 0.9912, missing rate 0.0000
Testing IVF Flat (baseline)
training
Training level-1 quantizer
Training level-1 quantizer on 100000 vectors in 128D
Training IVF residual
IndexIVF: no residual training
add
IndexIVFFlat::add_core: added 1000000 / 1000000 vectors
search
nprobe 1 0.022 ms per query, R@1 0.4139, missing rate 0.0300
nprobe 4 0.018 ms per query, R@1 0.6368, missing rate 0.0000
nprobe 16 0.035 ms per query, R@1 0.8322, missing rate 0.0000
nprobe 64 0.103 ms per query, R@1 0.9562, missing rate 0.0000
nprobe 256 0.332 ms per query, R@1 0.9961, missing rate 0.0000
Testing IVF Flat with HNSW quantizer
training
Training level-1 quantizer
Training L2 quantizer on 100000 vectors in 128D
Adding centroids to quantizer
Training IVF residual
IndexIVF: no residual training
add
IndexIVFFlat::add_core: added 1000000 / 1000000 vectors
search
nprobe 1 0.009 ms per query, R@1 0.4102, missing rate 0.0323
nprobe 4 0.014 ms per query, R@1 0.6327, missing rate 0.0000
nprobe 16 0.030 ms per query, R@1 0.8288, missing rate 0.0000
nprobe 64 0.094 ms per query, R@1 0.9545, missing rate 0.0000
nprobe 256 0.332 ms per query, R@1 0.9925, missing rate 0.0000
Performing kmeans on sift1M database vectors (baseline)
Clustering 1000000 points in 128D to 16384 clusters, redo 1 times, 10 iterations
Preprocessing in 0.07 s
Iteration 0 (36.15 s, search 36.12 s): objective=5.58803e+10 imbalance=1.737 nsplit=5 Iteration 1 (71.32 s, search 71.25 s): objective=4.11771e+10 imbalance=1.378 nsplit=0 Iteration 2 (107.25 s, search 107.15 s): objective=3.9914e+10 imbalance=1.301 nsplit= Iteration 3 (142.60 s, search 142.47 s): objective=3.93716e+10 imbalance=1.269 nsplit Iteration 4 (178.17 s, search 178.01 s): objective=3.9066e+10 imbalance=1.253 nsplit= Iteration 5 (214.30 s, search 214.11 s): objective=3.8872e+10 imbalance=1.243 nsplit= Iteration 6 (250.13 s, search 249.92 s): objective=3.87377e+10 imbalance=1.237 nsplit Iteration 7 (285.57 s, search 285.33 s): objective=3.86397e+10 imbalance=1.232 nsplit Iteration 8 (321.46 s, search 321.19 s): objective=3.85653e+10 imbalance=1.229 nsplit Iteration 9 (357.11 s, search 356.81 s): objective=3.8508e+10 imbalance=1.227 nsplit=0
Performing kmeans on sift1M using HNSW assignment
Clustering 1000000 points in 128D to 16384 clusters, redo 1 times, 10 iterations
Preprocessing in 0.07 s
Iteration 0 (11.13 s, search 10.96 s): objective=5.58887e+10 imbalance=1.737 nsplit=0 Iteration 1 (21.37 s, search 21.07 s): objective=4.11817e+10 imbalance=1.379 nsplit=2 Iteration 2 (31.33 s, search 30.89 s): objective=3.99504e+10 imbalance=1.301 nsplit=0 Iteration 3 (41.08 s, search 40.47 s): objective=3.93767e+10 imbalance=1.269 nsplit=2 Iteration 4 (50.91 s, search 50.17 s): objective=3.90675e+10 imbalance=1.253 nsplit=1 Iteration 5 (60.60 s, search 59.72 s): objective=3.88936e+10 imbalance=1.243 nsplit=0 Iteration 6 (70.48 s, search 69.46 s): objective=3.87889e+10 imbalance=1.236 nsplit=0 Iteration 7 (80.54 s, search 79.37 s): objective=3.8648e+10 imbalance=1.232 nsplit=1 Iteration 8 (90.33 s, search 89.03 s): objective=3.85683e+10 imbalance=1.229 nsplit=3 Iteration 9 (100.14 s, search 98.69 s): objective=3.85264e+10 imbalance=1.227 nsplit=1
Testing NSG Flat
add
IndexNSG::add 1000000 vectors
Build knn graph with NNdescent S=10 R=100 L=114 niter=10
Parameters: K=64, S=10, R=100, L=114, iter=10
Iter: 0, recall@64: 0.000000
Iter: 1, recall@64: 0.002969
Iter: 2, recall@64: 0.024531
Iter: 3, recall@64: 0.110781
Iter: 4, recall@64: 0.332656
Iter: 5, recall@64: 0.559375
Iter: 6, recall@64: 0.751094
Iter: 7, recall@64: 0.862188
Iter: 8, recall@64: 0.922656
Iter: 9, recall@64: 0.953906
Added 1000000 points into the index
Check the knn graph
nsg building
NSG::build R=32, L=64, C=132
Degree Statistics: Max = 32, Min = 1, Avg = 20.056442
Attached nodes: 0
search
search_L -1 0.008 ms per query, R@1 0.8152, missing rate 0.0000
search_L 16 0.011 ms per query, R@1 0.8849, missing rate 0.0000
search_L 32 0.017 ms per query, R@1 0.9528, missing rate 0.0000
search_L 64 0.032 ms per query, R@1 0.9843, missing rate 0.0000
search_L 128 0.051 ms per query, R@1 0.9959, missing rate 0.0000
search_L 256 0.086 ms per query, R@1 0.9993, missing rate 0.0000
hnswlib
Presentation
The Vamana Graph Construction Algorithm in DiskANN
